热点资讯
配资知识开户 CXL,最强科普
发布日期:2024-10-11 19:34 点击次数:161

摘要配资知识开户
Compute Express Link(CXL)是处理器与加速器、内存缓冲器、智能网络接口、持久内存和固态硬盘等设备之间的开放式行业标准互连。CXL 提供一致性和内存语义,其带宽可与 PCIe 带宽相匹配,同时延迟大大低于 PCIe。所有主要 CPU 供应商、设备供应商和数据中心运营商都已将 CXL 作为通用标准。这样就形成了一个可互操作的生态系统,支持包括高效加速器、服务器内存带宽和容量扩展、多服务器资源池和共享以及高效点对点通信在内的关键计算用例。本调查介绍了 CXL,包括 CXL 1.0、CXL 2.0 和 CXL 3.0 标准。我们将进一步调查 CXL 的实现情况,讨论 CXL 对数据中心环境的影响以及未来的发展方向。
1
引言
Compute Express Link(CXL)是一个开放的行业标准,定义了 CPU 和设备之间的一系列互连协议。虽然有 CXL 规范 [3] 和新闻机构的简短摘要,但本教程旨在提供技术细节,同时让广大系统受众易于理解。CXL 协议横跨整个计算堆栈,涉及计算机科学的多个分支。为了处理这种广泛性,我们将重点放在基础工程方面,而较少关注安全特性、安全影响和更高级别的软件功能。
作为一种通用设备互连,CXL 采用了广泛的设备定义,包括图形处理器 (GPU)、通用图形处理器 (GP-GPU)、现场可编程门阵列 (FPGA),以及各种专用加速器和存储设备。传统上,这些设备使用外围组件互连-Express®(PCI-Express® 或 PCIe®)串行接口。CXL 还针对传统上通过双倍数据速率(DDR)并行接口连接到 CPU 的存储器。
虽然 PCIe 和 DDR 对于各种设备来说都是很好的接口,但它们也有一些固有的局限性。这些限制导致了以下挑战,促使我们开发和部署 CXL:
挑战 1:连贯访问系统和设备内存。系统内存通常通过 DDR 连接,并可由 CPU 高速缓存分级缓存。相比之下,PCIe 设备对系统内存的访问是通过非一致性读/写实现的,如图 1 所示。PCIe 设备无法缓存系统内存以利用时间或空间位置性或执行原子操作序列。从设备到系统内存的每次读/写都要经过主机的根复用器 (RC),从而使 PCIe 与 CPU 的缓存语义保持一致。同样,连接到 PCIe 设备的内存从主机进行非一致性访问,每次访问都由 PCIe 设备处理。因此,设备内存无法映射到可缓存的系统地址空间。
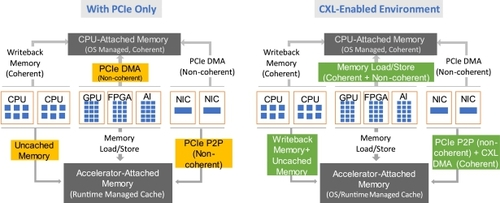
图 1. CXL 支持一致性和内存语义,建立在 PCIe 物理子系统之上。
非一致性访问对于流式 I/O 操作(如网络访问或存储访问)非常有效。对于加速器而言,整个数据结构在移回主存储器之前,会从系统内存移至加速器以实现特定功能,并部署软件机制以防止 CPU 和加速器之间的同时访问。这对人工智能 (AI)、机器学习 (ML) 和智能网络接口卡 (NIC) 等新的使用模式构成了障碍,在这些使用模式中,设备需要使用设备本地缓存与 CPU 同时访问相同数据结构的部分内容,而无需来回移动整个数据结构。这一挑战也出现在不断发展的内存处理(PIM)领域,该领域试图将计算迁移到数据附近[78]。目前,PIM 设备还没有标准化的方法来连贯访问 CPU 缓存层中的数据。这导致了繁琐的编程模型,阻碍了 PIM 的广泛应用[65, 66, 78]。
挑战 2:内存可扩展性。对内存容量和带宽的需求与计算量的指数增长成正比[17, 18, 27, 28, 31, 59, 60, 63]。遗憾的是,DDR 内存无法满足这一需求。这限制了每个 CPU 的内存带宽。造成这种扩展不匹配的一个关键原因是并行 DDR 接口的引脚效率低下。通过增加 DDR 通道进行扩展会大大增加平台成本,并带来信号完整性挑战。原则上,PCIe 引脚将是一个很好的替代方案,因为其单位引脚内存带宽更优越,即使会增加串行化/反串行化的延迟(如后面所讨论的)。例如,32GT/s 的 x16 Gen5 PCIe 端口可通过 64 个信号引脚提供 256 GB/s。DDR5-6400 的速度为 50 GB/秒,信号引脚为 200 个。PCIe 还支持使用重定时器1 实现更长的传输距离,这样可以将内存移到离 CPU 更远的地方,每个 DIMM 的功耗可超过 15 W,从而实现更出色的性能。遗憾的是,PCIe 不支持一致性,设备连接的内存无法映射到一致性内存空间。因此,PCIe 无法取代 DDR。
另一个扩展挑战是 DRAM 存储器的每比特成本最近一直保持不变。虽然有多种介质类型,包括托管 DRAM [69]、ReRam [70]、3DXP/Optane [71],但 DDR 标准依赖于特定于 DRAM 的命令进行访问和维护,这阻碍了新介质类型的采用。
挑战 3:绞合导致内存和计算效率低下。当今的数据中心由于资源搁浅而效率低下。当内存等资源仍处于闲置状态,而计算等资源已被充分利用时,就会出现资源搁浅。根本原因是资源耦合过紧,计算、内存和 I/O 设备只属于一台服务器。因此,每台服务器都需要超量配置内存和加速器,以处理峰值容量需求的工作负载。例如,一台服务器上的应用程序需要比现有内存(或加速器)更多的内存(或加速器),但这台服务器无法从同一机架上另一台未充分利用的服务器借用内存(或加速器),因此必须承受页面缺失带来的性能后果。然而,在所有内核都被工作负载使用的服务器上,经常会出现内存闲置的情况。搁浅对功耗[34]、成本[18]和可持续性[33]都有不利影响,也是阿里巴巴[27]、AWS[32]、谷歌[28]、Meta[17, 31]和微软[18, 29, 30]资源利用率低的原因。
挑战 4:分布式系统中的细粒度数据共享。分布式系统经常依赖于细粒度同步。底层更新通常较小,对延迟敏感,因为更新时会出现工作块。这方面的例子包括网络搜索、社交网络内容组合和广告选择等网络规模应用中的分区/聚合设计模式 [36, 37, 39, 40]。在这些系统中,查询更新通常小于 2 kB(如搜索结果)。其他例子包括依赖 kB 级页面的分布式数据库和更新更小的分布式共识 [35、42-44]。以如此精细的粒度共享数据意味着,典型数据中心网络中的通信延迟会影响更新的等待时间,并减慢这些重要用例的运行速度[36, 38]。例如,以 50 GB/秒(400 Gbit/秒)的速度传输 4 kB 的数据只需不到 2 秒,但在当前网络中,通信延迟超过 10 秒[38]。相干共享内存的实现有助于将通信延迟缩短到亚微秒级,稍后我们将看到这一点。
CXL 的作用。CXL的开发就是为了应对上述四项挑战和其他挑战。自 2019 年首次发布以来,CXL 已经发展了三代(见第 2 节)。每一代都规定了互连和多种协议(见第 3 节),同时保持完全向后兼容。表 1 概述了当前 CXL 的三代版本和主要用例示例。如图 1 所示,CXL 1.0 在 PCIe 物理层之上复用了一致性和内存语义。CXL 引入了定制链路层和事务层,以实现与远程插槽内存访问相当的低延迟。通过使 CXL 设备能够缓存系统内存,从而解决了挑战 1(一致性)和挑战 2(内存扩展)。这也使一致性接口标准化,促进了 PIM 系统和编程模型的广泛采用。CPU 还可以缓存设备内存,这也解决了异构计算的挑战 4(细粒度分布式数据共享)。此外,连接到 CXL 设备的内存可映射到系统可缓存内存空间。这有利于异构处理,并有助于应对内存带宽和容量扩展挑战(挑战 2)。CXL 1.0 还继续支持 PCIe 的非一致性生产者-消费者语义[1, 2, 8]。

表 1. CXL 规范世代、速度和用例概览
CXL 2.0 还通过在多台主机间实现资源池来解决挑战 3(资源搁浅)。我们使用主机来指单个操作系统或管理程序控制下的单插槽或多插槽系统。资源池通过将资源(如内存)重新分配给不同的主机,而无需重新启动这些主机,从而克服了资源搁浅和碎片化问题。CXL 协议通过引入 CXL 交换机来构建一个由主机和内存设备组成的小型网络,从而实现资源池。
CXL 3.0 通过多级 CXL 交换在更大范围内解决了挑战 3。这样就能在机架甚至 pod 层构建动态可组合系统。此外,CXL 3.0 通过实现跨主机边界的细粒度内存共享,解决了挑战 4(分布式数据共享)。
CXL 需要 CPU 和设备支持。几乎所有芯片供应商都在商业产品中广泛采用 CXL,这证明该技术因其解决实际问题的能力而受到广泛欢迎。这使得 CXL 在解决关键行业挑战方面走上了一条可行之路,并得到了广泛应用 [8、15、16、17、18]。CXL 3.0 也已经达到了一定的成熟度,有助于对其基本设计选择进行审查。本教程第 2 节介绍了背景。第 3、4 和 5 节分别详细介绍了 CXL 1.0、CXL 2.0 和 CXL 3.0 的增量版本。第 6 节讨论 CXL 的实现和性能。第 7 节讨论了更广泛的影响和未来发展方向。
2
用于未来光刻的EUV-FEL光源
高速缓存一致性互连历来是 "对称 "的,因为它们侧重于多插槽系统或多 GPU 系统。每个节点(CPU 或 GPU)都将实施相同的一致性算法,并跟踪所需的状态。常见的例子有英特尔的快速路径互连(QPI)和超级路径互连(UPI)、AMD 的 Infinity Fabric、IBM 的 Bluelink 和 Nvidia 的 NVLink。多年来,对称互联的多种扩展试图解决第 1 节中的一些难题,如 CCIX 和 OpenCAPI。一些公司还授权使用 QPI 等协议。然而,行业经验表明,对称高速缓存一致性的复杂性和性能要求给部署带来了巨大挑战,因为协调一致性的机制在不同的架构和设计选择中存在很大差异,而且随着时间的推移而变化。此外,并非所有用例都需要一致性支持,例如挑战 2(内存扩展)和挑战 3(搁浅)。
广泛采用还要求有一个即插即用的生态系统,能够与前几代产品和不同的系统架构兼容。事实证明,向后兼容性是二十多年来 PCIe 成功成为无处不在的 I/O 互连的主要原因之一。它为设备和平台制造商独立进行技术过渡提供了便利。例如,平台可能会迁移到 PCIe 第 5 代,而固态硬盘供应商可能会决定继续使用第 4 代,并在以后根据固态硬盘的技术发展进行迁移。这还有助于保护客户的投资,因为客户可能会在新平台中重复使用一些老一代设备,例如,为了减少碳排放[33, 81]。
在英特尔,在 PCIe 上添加简化一致性机制的想法可以追溯到 2005 年,其动机是加速器需要缓存系统内存。这导致交易处理提示使用 CPU 的高速缓存层次结构来加快设备访问速度,并在 PCIe 3.0 中添加原子语义,同时保持 PCIe 的非一致性。英特尔最初还打算在 PCIe 3.0 的基础上添加内存语义,以便通过共享内存控制器 (SMC) 实现池化。然而,PCIe 3.0 的带宽(8.0 GT/s)严重限制了使用一个 SMC 进行资源池的服务器数量。多 SMC 拓扑结构会因多次跳转而导致更高的延迟。另一个挑战是布线。2019 年,32.0 GT/s 的 PCIe 5.0(以及 64.0 GT/s 的 PCIe 6.0 的进展)和强大的电缆支持重振了英特尔的努力。英特尔由此推出了英特尔加速器链接(IAL):一种在 PCIe 5.0 上同时支持缓存和内存的专有协议。利用二十多年来开发 PCI-Express 的经验,英特尔捐赠了 IAL 1.0 规范,并于 2019 年 3 月与阿里巴巴、思科、戴尔、谷歌、华为、Meta、微软和 HPE 共同发起了 CXL 联盟。IAL 1.0 规范更名为 CXL 1.0 规范。
CXL 在一致性、向后兼容性和开放性方面采用了非对称方法,以实现多样化和开放的生态系统,促进广泛部署。CXL 一致性与特定于主机的一致性协议细节脱钩。主机处理器还负责协调缓存一致性,以简化设备一致性的实施。设备的高速缓存代理通过一个小命令集执行简单的 MESI(修改、独占、共享、无效)一致性协议。CXL 提供多种复杂程度不同的协议,支持多种用例,设备只能实施协议的一个子集(第 3 节)。
CXL 利用 PCIe 物理层,设备插入 PCIe 插槽。CXL 的向后兼容演进(如 PCIe)及其与 PCIe 的互操作性,确保了公司对 CXL 的投资可以保证与上一代 CXL 设备以及任何 PCIe 设备的互操作性。在 PCIe 基础架构上进行构建可实现 IP 构建模块、通道和软件基础架构的重复使用,从而降低了进入门槛。从 SoC 的角度来看,多协议功能 PCIe 物理层(如图 2 所示)有助于减少硅面积、引脚数和功耗 [1、2、8、9]。
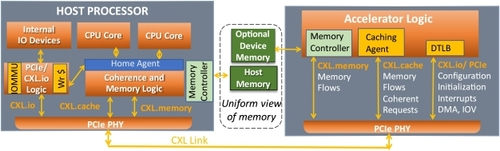
图 2. 利用 CXL 在 PCIe 物理层上动态复用三种协议 [8]。
CXL 于 2019 年推出时,行业内还存在 OpenCAPI、GenZ 和 CCIX 等相互竞争的互连标准。从那时起,CXL 成员已增加到约 250 家公司,所有 CPU、GPU、FPGA、网络、IP 提供商都在联盟内积极贡献力量。在英特尔于 2019 年 3 月捐赠 CXL 1.0 之后,该联盟于 2019 年 9 月发布了 CXL 1.1,增加了合规性测试机制。之后,联盟分别于 2020 年 11 月和 2022 年 8 月发布了 CXL 2.0 和 CXL 3.0,其中包括更多的使用模式,同时保持了完全的向后兼容性。随着时间的推移,行业已围绕 CXL 形成合力。例如,竞争标准 GenZ 和 OpenCAPI 向 CXL 捐赠了知识产权和资金,以支持共同标准。
3
CXL 1.1 协议
CXL 的第一代协议为直接连接到主机的设备引入了一致性和内存语义。这使得 CPU 和加速器能对共享数据结构进行细粒度异构处理(第 1 节中的挑战 1),并能以经济高效的方式扩展内存带宽和容量(第 1 节中的挑战 2)。
CXL 是一种非对称协议,与 PCIe 类似。主机处理器包含根复合体(RC),每个 CXL 链路一个,每个根复合体连接到作为 "端点 "的设备。主机处理器协调高速缓存一致性,如下所述。软件通过在主机处理器中执行的指令配置系统,主机处理器生成配置事务以访问每个设备。CXL 本机支持 x16、x8 和 x4 链路宽度,在降级模式下支持 x2 和 x1 宽度。降级模式是指 PCIe 链路自动进入更窄的宽度和/或更低的频率,以克服特定通道上高于预期的错误率。CXL 本机支持 32.0 GT/s 和 64.0 GT/s 的数据速率,降级模式下支持 16.0 GT/s 和 8.0 GT/s 的数据速率[1, 5, 8]。
图 2 说明了 CXL 如何与 PCIe 实现完全互操作,因为它使用的是 PCIe 协议栈。CXL 设备以 2.5 GT/s 的 PCIe 第 1 代数据速率启动链路训练,如果其链路合作伙伴支持 CXL,则使用 PCIe 5.0 和 PCIe 6.0 规范中定义的备用协议协商机制协商 CXL 作为运行协议。
3.1
CXL 协议和设备类型
CXL 使用三种协议实现,即 CXL.io、CXL.cache 和 CXL.memory(又名 CXL.mem),这些协议在 PCIe 物理层上动态多路复用。图 2 展示了 CXL 的多协议支持。CXL.io 协议基于 PCIe。它用于设备发现、状态报告、虚拟到物理地址转换和直接内存访问(DMA)。CXL.io 使用 PCIe 的非相干负载存储语义 [7、8、9]。现有的 PCIe 软件基础架构将通过必要的增强重新使用,以利用 CXL.cache 和 CXL.mem 等新功能。CXL.cache 用于设备缓存系统内存。CXL.mem 使 CPU 和其他 CXL 设备能将设备内存作为可缓存内存访问。CXL.mem 使连接到设备的内存成为可缓存内存(称为主机管理设备内存 (HDM)),类似于主机内存,从而实现主机在 HDM 和主机内存之间的统一视图(图 2)。如图 3 所示,CXL.io 对所有设备都是强制性的,而 CXL.cache 和 CXL.mem 则是可选的,并根据具体用途而定。
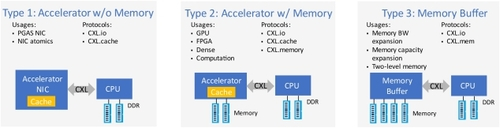
图 3. 三大类 CXL 终端设备[8]。
图 3 显示了 CXL 1.0/1.1 规范中定义的三种设备类型,它们捕捉到了不同的使用模式。类型 1 设备是智能网卡等加速器,使用一致性语义和 PCIe 式 DMA 传输。因此,它们只实施 CXL.io 和 CXL.cache 协议。类型 2 设备是 GP GPU 和 FPGA 等加速器,其本地内存可部分映射到可缓存系统内存。这些设备也缓存系统内存以进行处理。因此,它们执行 CXL.io、CXL.cache 和 CXL.mem 协议。第 3 类设备用于内存带宽和容量扩展,可用于连接不同类型的内存,包括支持连接到设备的多个内存层。因此,3 类设备将仅实施 CXL.io 和 CXL.mem 协议。CXL 第 3 类设备为服务器 CPU 增加更多 DDR 通道提供了一种成本、功耗和引脚效率高的替代方案,同时因其更长的线程长度而为系统拓扑结构提供了灵活性,从而缓解了电力传输和冷却方面的限制 [8,9]。
CXL 采用分层协议方法。物理层负责物理信息交换、接口初始化和维护。数据链路层(或链路层)负责可靠的数据传输服务,并在设备之间建立逻辑连接。事务层负责处理与每个协议相关的事务以及任何架构排序语义、流量控制和信用。这些层中的每一层都有一组寄存器,软件可访问这些寄存器来配置、控制和获取链路状态。读者可参阅相关规范[5, 7]了解详情。
3.2
CXL 68 字节 Flit
CXL 在 PCIe 物理层复用了三个协议。每个协议的传输单位都是一个 Flit(流量控制单元)。CXL 1.0、1.1 和 2.0 规范定义了一个 68 字节的 Flit [1、2、3、4、8、9]。CXL 3.0 规范引入了额外的 256 字节 Flit [5、6、7、8、9、13、14],第 5 节将对此进行讨论。每个 68 字节的 Flit 包括一个 2 字节的协议标识、一个 64 字节的有效载荷和一个保护有效载荷的 2 字节 CRC(循环冗余校验)(图 4(a))。协议标识符可划分不同类型的数据包,并具有内置冗余功能,可检测和纠正这 2 个字节内的多个位翻转。CRC 可保证在 64 字节有效载荷(加上 2 字节的 CRC)中检测到多达 4 个随机比特翻转,从而实现极低(<< 10-3)的故障时间(FIT,即链路中十亿小时内的故障次数),规范规定的误码率(BER)小于 10-12 [5,7]。图 4(b) 显示了 CXL.cache、CXL.mem 和 Arb/Mux 链路管理包 (ALMP) 使用的 16 字节插槽机制,其中 4 个 16 字节插槽构成了 Flit 的 64 字节有效载荷。Arb/Mux 向其链路伙伴的 Arb/Mux 设备发送 ALMP 数据包,以根据需要协调链路管理功能,如跨多个堆栈的电源管理。图 4(c) 显示了 CXL.cache 和 CXL.mem 协议使用的全数据 Flit 的布局,简称为 CXL.cache+mem,因为两者之间的区分发生在链路层,因为它们都是基于 Flit 的本地协议。CXL.io 使用 PCIe 事务/数据链路层数据包(TLP/ DLLP),这些数据包在 Flit 的有效载荷部分发送。由于 TLP 和 DLLP 有自己的 CRC(分别为 32 位和 16 位)[7],CXL.io 数据包的接收器会忽略 16 位 Flit CRC [2,3]。
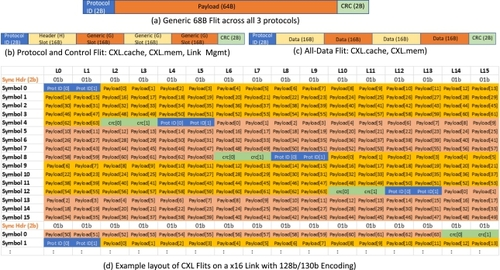
图 4. CXL 68 字节 Flit 布局 [2, 8]。
CXL.cache和CXL.mem的访问延迟很低,类似于本地CPU到CPU的对称一致性链路[1, 8, 9]。因此,CXL 设备的内存访问延迟类似于远程插座中 DDR 总线的内存访问延迟。虽然这比本地插槽中 DDR 总线的内存访问延迟要高[79],但在双插槽对称多处理系统中,由于 NUMA(非统一内存访问)的优化和更高的带宽,非空闲系统中的延迟较低[8, 9, 10],这种延迟是可以接受的。CXL.cache和CXL.mem的链路层和事务层路径具有较低的延迟,因为它们本身是基于Flit的,而且Flit的64字节有效载荷选择与这些协议的高速缓存行大小的传输相同。在物理层(PHY)级(而不是堆栈的更高级别)进行多路复用有助于为 CXL.cache 和 CXL.mem 流量提供低延迟路径。这消除了 PCIe/ CXL.io 路径链路层和事务层的较高延迟,因为它们支持可变数据包大小、排序规则、访问权限检查等,符合 CXL 规范的基本指导原则 [1,3]。物理层可区分 CXL.io、CXL.cache-mem、ALMP 和 NULL Flits(不发送任何内容)。在发送有序集之前,这四类 Flits 中的每一类都有两种情况来指示当前 Flit 是否是数据流的终点(EDS)。这些有序集由物理层注入,用于周期性时钟补偿或任何链路恢复事件等功能。这八种编码使用 8 位,保证汉明距离为 4,重复两次,以便进行校正和检测 [2,3]。每个有序集长一个区块(130 b),用于链路训练和时钟补偿。每个车道独立发送其有序集。
在以 32 GT/s 或更低的速度运行时,CXL 使用 PCIe 的 128 b/130 b 编码方案,在该方案中,每条线路上的每 128 位数据都预置 2 位同步头,以区分数据块和有序集块 [7,8]。如图 4(d)中 x16 链路的两个数据块所示,每个巷道上的 128 位数据有效载荷用于传输 Flits。一个 Flit 可以跨越多个数据块,一个数据块可以包含多个 Flits。由于 CXL.io 数据包(TLP 和 DLLP)本身不是基于 Flit 的,因此一个 TLP 或 DLLP 可以跨越多个 Flit,而一个 Flit 可能包含两个数据包。对这些开销进行描述,就能得到第 6.3 节讨论的有效载荷吞吐量。为了优化延迟,在协商 CXL 协议 [2] 时,如果链路的所有组件(包括 Retimers(如有))在初始 PCIe 链路培训过程中宣布支持该优化,则 CXL 可移除 2 位同步头。
3.3
CXL.io 协议
CXL.io 协议基于 PCIe,用于设备发现、配置、初始化、I/O 虚拟化和使用非相干负载存储语义的 DMA 等功能。与 PCIe 一样,CXL.io 也是一种基于信用的分批交易协议[7]。拆分事务是指与 CXL.io 请求事务相关的任何完成都会在稍后时间独立异步到达。这与早期基于 PCI 总线的架构不同,在早期的架构中,事务会锁定总线,直到其完成。之所以能做到这一点,是因为每个事务都是作为独立的事务层数据包(TLP)发送的,其消耗的 "点数 "与其在接收器上消耗的缓冲空间一致。有三种流量控制类别(FC):已发布((P),用于内存写入和信息)、非发布((NP),那些需要完成的,如内存读取和配置/I/O 读/写)和完成(C)。CXL.io 在这些 FC 上遵循 PCIe 排序规则,如图 5 所示(CXL 3.0 引入了这些排序规则的例外情况,详见第 5 节)。这些规则可确保向前推进,同时执行生产者-消费者订购模式。CXL.io 规定了两个虚拟通道,以确保服务质量(QoS)。具有不同要求和延迟特性的流量被放置在不同的虚拟通道(VC)中,以尽量减少系统中队列顶部阻塞的影响。例如,带宽大流量与对延迟敏感的等时流量可以放在不同的虚拟通道中,并且可以设置不同的仲裁策略。同样,我们可以将 DRAM 访问和持久内存访问放在两个不同的虚拟通道中,因为它们的延迟和带宽特性截然不同,以确保其中一个通道的流量不会影响另一个通道。
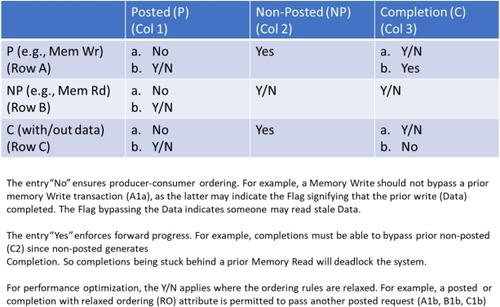
图 5. CXL 1.1 的 PCI-Express/ CXL.io 排序表,其中 "是 "表示事务(第 2 次传输)可以超越之前的事务(第 1 次传输),以确保向前推进。为确保生产者-消费者排序,"否 "表示不允许超越。为优化性能,"Y/N "适用于排序规则放宽的情况。
图 6(a) 描述了作为硬件和软件之间契约的生产者-消费者排序模型。这种模式在整个系统中强制执行,即使是跨越不同层次的事务,以及位于不同内存位置并可能具有不同属性(如可缓存与不可缓存)的地址位置也不例外。设备可以是 CPU、CXL/PCIe 设备或交换机中的任何实体。基本原理是,生产者产生(内存写入)数据,随后写入标记;数据和标记可以位于系统中的多个内存位置。如果消费者看到标记,就可以读取数据,并确保获得生产者写入的最新数据。标志可以是系统内存中的环形缓冲区、设备中的内存映射 I/O 位置或发送到处理器的中断。图 5 中描述的排序规则确保了生产者-消费者排序模式。排序规则的另一个作用是设备同步使用,如图 6(b) 所示。在这里,两个设备可能正在执行两个任务,并将 A 和 B 作为它们完成任务的指示器。如果读取获得的是旧数据,那么该设备中的进程可以暂停,由稍后完成执行的设备重新安排。如果(a,b)是可能的,那么两个设备中的两个进程都将永远暂停,这是不希望看到的结果。

图 6. CXL.io 和 PCIe 中的生产者-消费者订购模型。
虽然 CXL.io/PCIe 排序模型可用于某些类型的同步,但图 6(c) 所示的同步用法无法通过流水线访问来执行,因为写入可以绕过之前的读取。这种限制导致具有分区全局地址空间(PGAS)的智能网卡在排序重要时,在读取后序列化写入。CXL.cache 克服了这一限制: 设备可以不按顺序预取所有数据,并在符合程序顺序的本地高速缓存中以低延迟完成事务。
CXL.cache+mem 大部分是无序的,但在每个高速缓存行上有一些排序限制,这将在后面讨论。在支持源-目的对之间多路径的拓扑结构中,这些限制可以通过路由机制来解决,该机制可确保任何给定高速缓存行的相关事务始终遵循相同的路径。但是,传统 PCIe(和 CXL.io)的排序要求是在整个内存空间内进行的。因此,传统 PCIe(以及 CXL)必须遵循树状拓扑结构。在 CXL 3 中,我们放宽了 CXL.io 的排序要求,可以支持任何结构拓扑,详见第 5 节。
CXL.io 使用标准 PCIe DLLPs 交换信息,如积分、可靠的 TLP 传输、电源管理等 [2、3、7]。CXL.io 使用 PCIe 的配置空间,并为 CXL 的使用对其进行了增强。这有助于使用现有的设备发现机制。我们预计,PCIe 设备驱动程序将进行必要的增强,以利用 CXL.cache 和 CXL.mem 等新功能,而系统软件将对与新功能相关的新寄存器集进行编程。这建立在现有基础设施的基础上,使生态系统更容易采用 CXL。
3.4
CXL.cache 协议
CXL.cache 协议使设备能够使用 MESI 一致性协议[47]缓存主机内存,缓存行大小为 64 字节。为了保持协议在设备上的简单性,主机管理所有对等缓存的一致性跟踪,而设备从不与任何对等缓存直接交互。该协议建立在每个方向的 3 个通道上。通道的方向是主机到设备(H2D)和设备到主机(D2H)。每个方向都有一个请求、响应和数据通道。通道在每个方向上都是独立流动的,但有一个例外:主机在 H2D 请求通道中发出的窥探(Snoop)信息必须在 H2D 响应中针对相同的高速缓存行地址推送之前的全局观察(GO)信息。GO 信息向设备指出一致性状态(MESI)和一致性承诺点。
CXL.cache 仅使用主机物理地址。缓存设备与中央处理器一样,在执行代码时使用虚拟地址。同样,高性能设备也应使用虚拟地址,以避免软件层提供转换。预计设备将实施与 CPU 的 TLB 类似的设备转换旁路缓冲器(DTLB),以缓存页表条目。它使用 PCIe(和 CXL.io)的地址转换服务(ATS)[2, 3, 5, 7]来获取虚拟到物理的转换以及访问控制,以确保多个虚拟机/容器之间的适当隔离。此外,CXL 还对 ATS 进行了扩展,以传达对地址的访问是允许使用 CXL.cache 还是仅限于 CXL.io。由于 DTLB 是非相干的,ATS 希望主机处理器跟踪整个平台上 DTLB 中的待处理条目,并对软件已失效的 DTLB 条目(或条目)启动失效。主机处理器使用其 ATS 硬件机制完成与 DTLB 的无效握手,然后再向正在使页表条目无效的软件指示完成。
D2H 请求通道包括 15 条命令,分为四类: 读取、读取 0、读取 0-写入、写入。如图 7 所示,"读 "类别允许设备请求高速缓存行的一致性状态和数据。响应将是 H2D 响应通道中的一致性状态(如果需要一致性)和 H2D 数据。读 0 "类请求只针对一致性状态,数据为 "0"(表示不需要数据)。它可用于升级高速缓存中的现有数据(S 到 E),或在预计写入整个高速缓存行时引入 E 状态。H2D 响应通道表示主机提供的一致性状态。读0-写 "类别允许设备直接向主机写入数据,在发出之前不需要任何一致性状态。当主机准备好接受 D2H 数据时,H2D 响应将显示 "WritePull",主机将在显示系统全球观测 (GO) 数据之前解决一致性问题。写 "类别用于设备从设备缓存中删除数据。这些请求可以是脏数据(M 状态),也可以是清洁数据(E 或 S 状态)。在设备需要提供数据的情况下,主机将指示 "WritePull",并指示 GO。
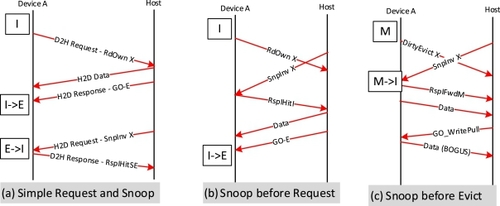
图 7. CXL 1.1 高速缓存协议流程。
H2D 请求通道用于主机改变设备的一致性状态,即 "窥探"(缩写为 Snp)。设备必须根据窥探类型的要求更新其缓存,如果缓存中存在脏数据(M-state),还必须将该数据返回给主机。图 7 举例说明,主机发送 SnpInv X,要求设备使地址 X 的高速缓存失效。设备将地址 X 的高速缓存状态从 E 改为 I,然后在 D2H 响应通道上发送 RspIHitSE。RspI 表示其最终缓存状态为 I 状态,HitSE 表示缓存在降级为最终 I 状态之前为 S 或 E 状态。
一致性协议的一个重要组成部分是如何处理对同一地址的冲突访问。有两种情况值得强调:(1) Req-to-Snoop 和 (2) Eviction-to-Snoop。要解决 Req-to-Snoop 情况,H2D 响应通道上的 GO 消息必须排在对同一高速缓存行地址的任何未来 Snoop 之前,以确保设备在处理 Snoop 之前观察主机提供的高速缓存状态(如有)。其原因如图 7(a) 所示,主机发送的 GO 消息必须在后面的窥探之前被观察到,这样设备才能意识到它已独占了该地址的所有权,并能正确处理窥探。图 7(b) 是顺序相反的情况,即主机首先处理窥探,并在窥探完成前停止处理未来的请求,因此设备在 GO 之前观察到窥探会导致在缓存处于无效状态时处理窥探。就 Evict-to-Snoop 而言,图 7(c) 显示了当 DirtyEvict 未处理时 snoop 到达的情况,设备必须用当前的 M 状态数据回复 snoop。稍后的 GO_WritePull 仍必须返回数据,但包括数据是假的(意味着可能是过期数据)的提示,因此主机必须放弃数据,因为更新的数据可能存在于其他代理中。
3.5
CXL.mem 协议
内存协议使设备能够公开主机管理的设备内存(HDM),允许主机管理和访问该内存,类似于连接到主机的本地 DDR。该协议独立于内存媒体,使用一组简单的主机物理地址2 读取和写入,要求设备内部转换为设备的媒体地址空间。该协议固有的 CXL 附加内存容量是有限的;实际上,限制来自于可附加 CXL 设备的数量和大小。对于希望同时缓存该内存的加速器设备,提供了高级语义,使设备能够直接缓存内存,并依靠设备跟踪主机对该内存的缓存。
该协议在每个方向上使用两个通道,分别称为主控对从属(M2S)和从属对主控(S2M)。M2S 方向提供一个请求通道和一个带数据的请求(RwD)通道。S2M 方向提供非数据响应(NDR)通道和数据响应(DRS)通道。为了实现简单/低延迟,通道之间没有排序。
CXL.mem 的两种使用情况是 (1) 作为 "主机内存扩展器",(2) 作为暴露给主机的加速器内存。两者都使用 HDM 术语来描述 CXL.mem 协议访问的内存区域,但协议要求有所不同。为了识别这些要求,后缀"-H "修饰符(HDM-H)表示主机内存扩展器是 "仅主机一致性 "的,"-D "修饰符(HDM-D)表示暴露给主机的加速器内存是 "设备管理一致性 "的3 HDM-H不包括任何一致性协议假设,而HDM-D包括每个报文中使用的高速缓存状态和高速缓存窥探属性。HDM-D 还需要一种方法,用于从设备向主机传送所需的内存高速缓存状态,称为 "偏置翻转 "流(Bias Flip Flow)4。
HDM-H 可选为每个高速缓存行提供 2 位元值,供主机使用。可能的用途包括一致性目录、安全属性或数据压缩属性。图 8(a) 显示了一个示例流程,主机读取更新设备中的元值,设备返回元值的先前状态。在此示例中,设备需要更改存储在设备中的当前元值,因为值已从 2(旧值)变为 0(新值)。请注意,内存介质存储的元值和 ECC(纠错码)位是针对特定设备的。
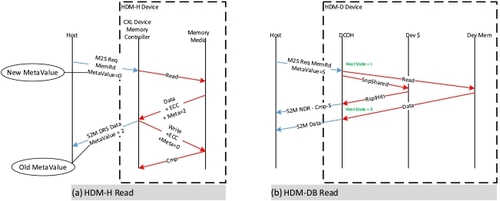
图 8. CXL 1.1 内存协议流程。
HDM-D 使用元值字段的方式不同,它在该字段中向设备公开主机一致性状态,这样设备就能知道主机为 HDM-D 区域中的每个地址缓存的状态。本规范使用 "设备一致性 (DCOH) 代理 "一词来描述设备中管理/跟踪设备与主机之间一致性的代理。图 8(b) 显示了 HDM-D 的一种情况,即主机在 S 状态下向高速缓存读取数据,并要求设备检查其高速缓存(Dev ∃)的当前副本,但在本例中,高速缓存中没有数据,因此数据是从主机内存中传送的。
HDM-D 一致性模型允许设备使用 CXL.cache 请求改变主机状态。CXL.cache 是实现这一功能的自然方式,因为 HDM-D 仅针对类型 2 进行了定义。设备改变主机高速缓存状态的流程被称为 "偏置翻转 "流程。图 9 是该流程的一个示例。设备向主机发送 "RdOwnNoData X"。主机检测到地址 X 是由发出设备拥有的 HDM-D 地址,其行为将与原来不同,因为它会直接改变主机的缓存状态,迫使所有主机缓存进入 I 状态。偏置翻转 "流的响应与传统的 CXL.cache 响应不同,在本例中,主机将在 CXL.mem M2S Req 信道上发送响应 MemRdFwd 消息,以表明主机已完成缓存状态更改。通过使用 CXL.mem M2S Req 通道,可以避免与主机之间的竞争条件,因为未来对同一地址的 CXL.mem 请求要求 M2S 请求通道排序才能访问同一高速缓存行。排序要求仅适用于 HDM-D 地址。
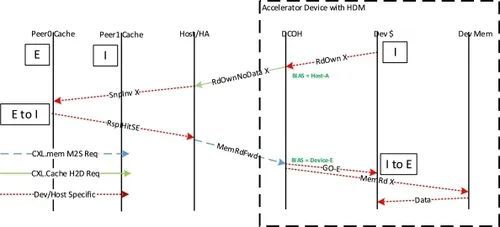
图 9. HDM-D 偏置翻转流程。
3.6
协议层次
CXL 与 CPU 内部的一系列一致性实现兼容。图 10(a)捕捉了一个可能的主机 CPU,其中 CXL.cache 位于与 CPU 内核共享的主机 L3 cache 下。在此示例中,CXL.io/PCIe 协议访问主机内存时也会通过相同的高速缓存,并遵循主机内存路径上使用的目标一致性语义。本图显示的是插座中的单个 L3。另外,主机架构也可以拆分 L3 或其他内部高速缓存,但不会对 CXL.cache 产生影响,因为 CXL.cache 不了解主机高速缓存的详细信息。根据主机特定协议(专有 CPU-to-CPU)的定义,主机可扩展到多个 CPU 插座或高速缓存,该协议定义了一个内部主代理,以解决主机高速缓存(包含 CXL.cache 设备)之间的一致性问题。该主机主代理可包括用于解决一致性问题的主机特定优化,如片上窥探过滤器或内存目录状态。CXL.mem 协议位于主机主代理逻辑之后,可支持仅主机一致性(HDM-H)或设备一致性(HDM-D)的简单内存扩展。对于 HDM-D,在主机主代理之后还包括一个额外的一致性解决级别,允许设备成为设备所拥有地址一致性的最终仲裁者。
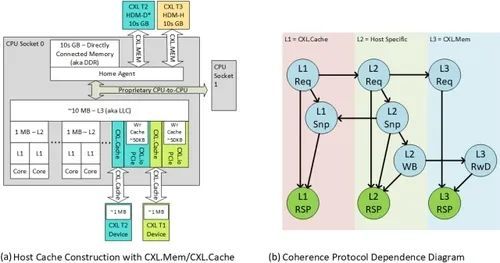
图 10. CXL 协议层次结构。
图 10(b) 显示了 CXL 中预期的协议依赖图。协议依赖图定义了哪些协议通道可能会被其他协议通道依赖(或阻塞)。如果没有产生循环依赖关系,依赖关系图是显示通道间死锁自由度的一种方法。依赖关系图中的一个例子是,L1 Req 可能依赖于 L1-Snp 通道完成,然后才能处理新的 L1 Req。之所以存在这种依赖关系,是因为请求可能需要先发送并完成窥探,然后才能完成请求。L1 协议是 CXL.cache 中提供的通道的抽象,其中 L1-Req 映射到 D2H Req,L1-Snp 映射到 H2D-Req,L1 RSP 映射到 H2D/D2H RSP 和数据通道,这些通道已预先分配给主机或设备,从而将这两个通道结合起来,形成依赖关系图。L2 协议是针对主机的,以主机可能存在的通道为例,但也可以选择其他通道。如果依赖关系图不存在循环,主机还可以包含其他级别的协议。L3 协议为 CXL.mem,其中 L3 Req 映射到 M2S-Req,L3-RwD 映射到 M2S-RwD,而 L3-Rsp 则覆盖预分配的 S2M NDR 和 DRS 信道。依赖关系图是一种用于显示协议中和协议间的法律关系和依赖关系的方法,可快速确定 CXL 本身以及主机或设备内部协议选择的高级死锁自由度。
4
CXL 2.0 协议
CXL 第二代实现了资源池功能,可在一段时间内将相同的资源分配给不同的主机。在运行时重新分配资源的能力解决了资源搁浅问题(第 1 节中的挑战 3),因为它克服了资源与单个主机之间的紧密耦合。如果一台主机运行计算密集型工作负载,但没有使用从池中分配的设备内存,那么操作员可以将该设备内存重新分配给另一台主机,后者可能运行内存密集型工作负载。由于操作员在设计时通常不知道哪些工作负载在哪些主机上运行,因此资源池可以节省大量内存: 操作员无需根据任何类型的内存密集型工作负载所使用的最坏情况内存容量来确定两台主机的大小,而是根据平均情况提供内存[18]。同样的池结构也适用于加速器等其他资源。
4.1
CXL 2.0 协议增强功能
CXL 2.0 增加了热插拔、单级交换、内存 QoS、内存池、设备池和全局持续刷新(GPF)。CXL 1.1 不允许热插拔,这就排除了在平台启动后添加 CXL 资源的可能性。CXL 2.0 支持标准 PCIe 热插拔机制,实现了传统的物理热插拔和动态资源池。
为支持单级切换,CXL 对 HDM 解码器中 CXL.mem 地址区域的地址解码进行了标准化。分层解码遵循 PCIe 内存解码模型,允许在每个交换机上进行解码,避免主机或交换机对分层中的所有代理进行完全解码。为支持多主机连接并启用设备池,每台主机都将 CXL 拓扑表示为一个虚拟层次结构(VH),其中包括交换机、主机端口的虚拟网桥以及具有设备资源的每个端口。如图 11 所示,每台主机都会看到一个单独的 VCS(虚拟 CXL 交换机),其中包括分配给该主机的设备的网桥。流量会根据 VH 中的活动虚拟网桥路由到设备。这就限制了 CXL 2.0 的有向树拓扑结构,每个主机和设备之间最多只有一条路径。此外,由于需要在交换机中跟踪每个 VH 的地址映射,CXL 3.0 克服了这一限制(第 5.4 节)。配置和更改 VH 将在第 4.2 节中介绍。
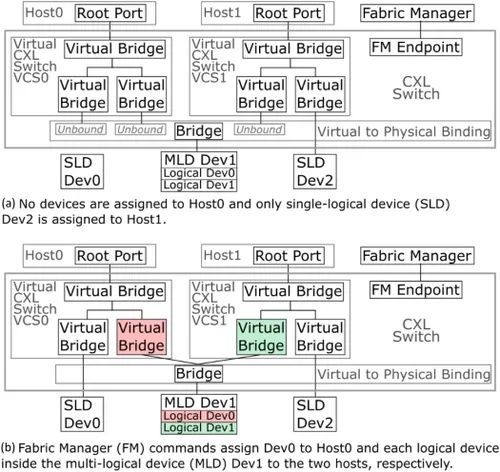
图 11. 具有两个虚拟层次结构的 CXL 交换机示例。
设备池建立在多主机交换机支持的基础上,允许设备一次动态分配给一台主机。标准设备一次分配给一台主机,称为单逻辑设备(SLD)。CXL 还定义了多逻辑设备(MLD),允许将单个 CXL.mem 设备的资源划分为逻辑设备(最多 16 个),同时分配给不同的主机。MLD 中的每个逻辑设备都可分配给不同的主机。CXL 3.0 引入了名为 "动态容量设备 "的扩展,灵活性更高。MLD 中的每个逻辑设备 (LD) 都由一个标识符 (LD-ID) 标识。这种扩展只在交换机和设备之间的链路上可见,主机看不到。主机将 LD-ID 字段留空。CXL 交换机根据主机端口将 LD-ID 标签应用于主机的 CXL.io 和 CXL.mem 事务。
由于交换、MLD 和潜在的不同类型内存(可能不是基于 DRAM),单个交换机中的资源可能会被过度占用,从而导致 QoS 问题。例如,一台设备的低性能可能会导致使用交换机的所有代理出现拥塞。为缓解这一问题,CXL 2.0 在 CXL.mem 响应信息中引入了 DevLoad 字段,以告知主机在其访问的设备中观察到的负载。主机应使用此负载信息来降低向该设备发送 CXL 请求的速率。CXL 规范定义了一个参考模型,即在高负载或临界负载时降低注入速率,直到达到额定负载;在轻负载时,主机可提高注入速率,直到达到额定负载。
如果有多个 CXL 请求注入点(例如,在 CXL 2.0 池方案中),则通过源节流提供 QoS,控制每个源可消耗多少 MLD 资源。对于非共享资源,可通过确保不同 VH(或 PBR 目的地)的事务能够在不相互依赖的情况下进行,来隔离每个 VH。CXL 协议还定义了一个遏制模型,确保如果端点设备没有响应,受影响的 VH 将通过对主机内未完成的访问生成错误响应来遏制错误,以避免主机超时,否则可能导致 VH 故障。
CXL 还定义了内存设备的错误报告,包括毒药数据支持。虽然确切的纠错码取决于内存介质的类型以及使用模式和平台,但对已纠正的错误和已检测到但未纠正的错误都进行了报告定义。报告已标准化,以便软件采取必要的措施[3, 5]。
4.2
设备库管理
池管理是指在运行时将 CXL 设备分配给主机。该标准使用术语 CXL Fabric Manager (FM) 来表示做出分配决策的应用逻辑和策略。实际上,FM 可以是主机上运行的软件、嵌入在底板管理控制器 (BMC) 或 CXL 交换机内的固件或专用设备。FM 通过使用组件命令接口 (CCI) 将(逻辑)设备分配给主机。这既可以在带内进行,例如通过内存映射输入/输出(MMIO),也可以通过管理组件传输协议(MCTP)在带外进行。MCTP 支持多种带外通信,包括 SMBus/I2C、PCIe、USB 和串行链路。
FM 通过绑定命令将设备分配到主机,该命令需要四个参数:CXL 交换机 ID、虚拟网桥 ID、物理端口 ID 和逻辑设备 ID(SLD 为空)。FM 将此命令发送到指定的交换机,交换机会检查该物理端口当前是否未绑定。如果未绑定,交换机将更新其内部状态以执行绑定。然后,它会向主机发送热添加指示,最后通知 FM 绑定成功。虚拟网桥和相关设备现在出现在主机的虚拟层次结构中。图 11(a) 和图 11(b) 之间显示了这种过渡。
对于 MLD,FM 可能需要首先通过 Set-LD 命令配置逻辑设备。该命令根据内存粒度(如 256 MB)和多个内存范围创建 LD。当 FM 没有与 MLD 的带外连接时,可通过 CXL 交换机传输该命令。创建 LD 后,FM 可以使用绑定命令将其分配给一台主机,并使用相应的 LD-ID 进行绑定。
要撤销设备分配,FM 可使用 unbind 命令,该命令需要三个参数:CXL 交换机 ID、虚拟网桥 ID 和 unbind 选项。解除绑定选项表示如何执行解除绑定,包括等待主机停用端口、热移除并等待主机或强制热移除。利用最后一个选项,FM 可以处理不合作的主机,例如由于故障或分配给裸机云中的第三方客户的主机。
除了这里介绍的三种命令外,FM 还支持 19 种其他命令。它们包括 QoS 控制,如在 MLD 内的逻辑设备之间分配带宽。这些命令还包括识别交换机端口和设备以及查询和配置其状态的方法(参见参考文献 [3] 中的表 205)。
4.3
主机软件支持
尽管大部分 CXL 都是在主机外部的硬件和软件(如调频)中实现的,但主机软件在支持 CXL 方面仍发挥着重要作用。在高层次上,系统固件会枚举和配置启动时存在的 CXL 资源。操作系统(OS)枚举和配置运行时连接和分离的 CXL 资源,例如热添加和热删除的内存地址范围。因此,操作系统在支持 CXL 2.0 方面发挥着重要作用。
传统上,资源拓扑和亲和性通过静态 ACPI(高级配置和电源接口)表进行通信。例如,NUMA(非统一内存访问)域在 SRAT(静态资源亲和表)表中定义,内存带宽和延迟在 HMAT(异构内存属性表)表中定义。通常情况下,这些表由固件配置,固件在启动时了解所有资源5。在 PCIe 中,这个问题比较简单,因为插入设备不会影响系统映射的内存。而在 CXL 中,需要为运行时连接的内存传递特定于内存的资源特性。在 CXL 供应商和设备的生态系统中,事先定义配置是不可行的。CXL 2.0 引入了相干设备属性表(CDAT),该表描述了内部 NUMA 域、内存范围、带宽、延迟和内存使用建议[45, 46]。当内存(逻辑)设备在运行时被热添加时,主机会读取相关的 CDAT 寄存器,操作系统会分配一个空闲的 HPA(主机物理地址)范围,并对 HDM 解码器进行编程。
5
CXL 3.0 协议


从假想图上可以看出,新车将采用分层式的LED前大灯,并采用上下分体式的菱形中网,给人感觉非常的有气势,力量感十足。新车的整体线条非常的硬朗,与现款途昂风格较为类似。车门位置采用隐藏式门把手,让整车显得更有气质。车尾预计将采用隐藏式的布局,上方保留了LED尾灯组。
为了应对大型分布式系统中的数据共享挑战(挑战 4),CXL 3.0 将 CXL 2.0 中引入的资源池扩展到更大规模,利用更大的 Flit 大小、低延迟和足够的带宽,为多达 4,096 个终端设备提供多级交换和协议支持。终端设备可以是代表独立服务器或节点的主机 CPU、内存、加速器或任何其他 I/O 设备(如网卡)。如图 12 所示,总体目标是根据工作负载动态组合系统,以较低的总体拥有成本提供高能效性能。为实现这些目标,CXL 3.0 引入了以下内容:
1.将每引脚带宽增加一倍,同时保持扩展到更大拓扑所需的延时不变。
2.支持 Fabric 拓扑: 这是所有负载存储互连标准中首次支持事务之间的排序限制。CXL 在任何源-端对之间都有多条路径,摆脱了树状拓扑结构的限制,这对扩展到数千台设备至关重要。这使得延迟更低、分段带宽更高、故障切换能力更强。
3.从 PCIe/CXL 设备直接点对点访问由 2 类/3 类设备托管的相干 HDM 存储器,如果不发生冲突,无需涉及主机处理器。因此,延迟低、拥塞少、带宽效率高,这对大型系统至关重要。例如,在图 12 中,使用直接 P2P,网卡到内存的距离为 8 跳,而通过 CPU 的距离为往返 16 跳。
4.跨主机共享一致的内存和信息传递: 这可以通过硬件或软件实现。共享一致性内存可使多个系统共享数据结构、执行同步或使用低延迟负载存储语义传递消息。信息传递也可以通过使用负载存储 CXL.io 语义(相对于延迟较高的网络语义)来完成。
5.近内存处理,允许在内存附近执行计算,以提高性能和能效。
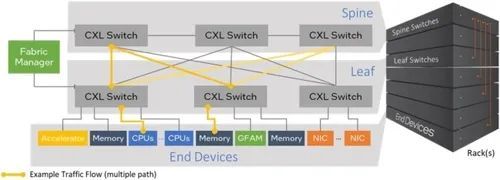
图 12. CXL 3.0 支持多路径的 Fabric 拓扑,可跨越一个或多个机架,从而实现可组合的横向扩展系统,在对等机架之间共享内存和负载存储信息传递。
5.1
支持数据速率翻番至 64.0 GT/s 的 Flit 格式化
CXL 3.0 基于 PCIe 6.0 规范 [5,6,7],使用 PAM-4(脉冲幅度调制 4 级)信令支持 64.0 GT/s。PAM-4 采用四级电压对每个单位间隔 (UI) 的两个比特进行编码,由于降低了眼高和眼宽(即电压和时间),因此错误率非常高[13, 14]。为了克服这一问题,PCIe 6.0 规范采用了 10-6 的首次突发错误率,并引入了 256 字节的 Flit(图 13(a)),其中包括 236 B TLP 和 6 B 数据链路包 (DLP) 的有效载荷由基于 GF(28) 上的里德-所罗门码的 8 B CRC 保护,而整个 250 B 则由每路 2 B 的 3 向交错单符号正确前向纠错码 (FEC) 保护[7, 14]。64.0 GT/s 速率的 CXL 3 使用相同的电气层和 256 B Flit,但做了一些修改。如图 9(b)和图 9(c)所示,对于 256 B 大小的 Flit 的两种变体,它保留了与 PCIe 相同的 FEC 机制。

图 13. 三种类型的 CXL 3.0 Flits。一个 256 B 的延迟优化 Flit (C) 由两个 128 B 的 Sub-Flits 组成,每个 Sub-Flits 在 256 B 之间具有共同的 FEC,但具有单独的 CRC。
图 13(b)显示了 CXL 3 中常规 256 B Flit 的布局。8 B CRC 与 PCIe 6.0 相同。唯一不同的是 2 B Hdr(Header)(DLP 前两个字节的增强版,用于可靠的 Flit 传输管理,如确认、重放请求、带序列号的重放)得到了增强,以指示 Flit 类型(CXL. DLP(用于可靠的 Flit 传播管理,如确认、重放请求、带序列号的重放)被增强,以指示 Flit 类型(CXL.io、CXL.cache+mem、ALMP、Idle)和可靠的 Flit 传播管理控制,并被置于 Flit 的起始位置,以管道方式将 Flit 传播到相应的协议栈,而无需累积整个 256 B Flit 以减少延迟。可选的延迟优化(LO)256 B Flit,如图 13(c)所示。LO Flit 被细分为两个子 Flit,每个 128 B,奇数 Flit-半中有 FEC,偶数 Flit-半中有 2 B Flit Hdr。每个半字节中都有一个 6 B CRC。如参考文献 [5, 13, 14] 所述,这 6 B CRC 源自 8 B CRC,以减少门数。第一个 6 B CRC 保护偶数位半中的 2 B Flit Hdr 和 120 B 数据,第二个 6 B CRC 保护奇数位半中的 116 B 数据。如果偶数半比特的 CRC 通过,就可以按顺序处理,而无需等待奇数半比特。如果奇数 Flit-half 的 CRC 通过,则可以处理奇数 Flit-half,前提是偶数 Flit-half 已经处理完毕(即没有 CRC 错误)。由于 CRC 大约需要 10 级逻辑门,而 FEC 需要 50 级逻辑门[14],因此在 x16 链路[13]上,先应用 CRC 有助于将延迟时间缩短 2 纳秒。此外,128 B 以上的 CRC 使累积延迟略好于 32 GT/s 的 68-B Flit 累积延迟。如果检测到错误,则累积整个 Flit,应用 FEC,然后再次应用 CRC。有关 Flit 以及 FEC 和 CRC 机制的详细信息,请参阅参考文献 [5、7、13、14]。
使用的 Flit 类型(68 B、256 B、LO)在协商使用 8 b/10 b 编码的 CXL 协议时预先协商。任何 CXL 设备都必须支持 68 B Flit。如果 CXL 设备支持 64.0 GT/s 数据传输速率,则还必须公布 256 B Flit 模式,而 LO Flit 模式支持的公布是可选的。如果链路的所有组件(两个设备以及中间的任何重定时器)都支持 LO Flit 模式,则会选择 LO;否则,如果所有组件都支持 256 B Flit,则会选择 256 B Flit 模式;否则,将支持 68 B Flit 模式。一旦在早期协商过程中选择了一种 Flit 模式,无论运行的数据速率如何,都将使用该模式。假设我们选择了 LO Flit 模式,因为链路中的所有组件都支持该模式和 64.0 GT/s,但如果链路以 32.0 GT/s 运行(例如,在 64.0 GT/s 时出现节能速度下移或链路稳定性问题),则仍将使用 LO Flit 模式。
对于 CXL.io,"数据 "的最后 4 B 将用于 DLLP(相当于 PCIe 6.0 中 6 B DLP 的最后 4 B [7,14])。这样,在 256 B Flit(与 PCIe 6.0 Flit 相同)模式下,TLP 的容量为 236 B,而在 LO Flit 模式下,TLP 的容量为 232 B。对于 ALMP,大部分 "数据 "字段是保留的。对于 CXL.cache-mem,插槽排列如图 14 所示。H 插槽和 G 插槽的用途与 68-B 相同(即 H 插槽或标头插槽仅用于标头,而 G 插槽或通用插槽用于标头或数据),但 H 插槽中的额外 2 B 用于构建更大的拓扑结构。HS 插槽只有 10 B,用于 2DRS 或 2NDR 等小型报头。

图 14. 256 B 和 LO Flits 的 CXL.cache 和 CXL.mem 插槽[8]。
5.2
CXL 3.0 的协议扩展:
支持 Fabric 的无序 I/O (UIO) 和反向无效 (BI)
第 3 节中描述的 PCIe 排序规则排除了任何非树形拓扑,这意味着 CXL 网络中的任意两个节点(主机或设备)之间只有一条路径。我们需要在任何一对源-目的节点之间建立冗余的多条路径,以创建性能良好的大型分布式系统。由于软件依赖于 "生产者-消费者 "排序模型,因此 CXL 协议需要在适应非树状拓扑的同时保留这种排序模型。CXL 3.0(以及 PCIe)通过在一个或多个不同的虚拟通道(VC,见第 3.1 节)上引入 "无序 "读/写/完成事务,并将排序执行权仅转移到源节点,从而解决了这一难题。每个虚拟通道都独立于其他虚拟通道,每个虚拟通道包括三个流控制(FC)类别: 已发布(P)用于内存写入等事务,非发布(NP)用于内存读取等事务,完成(C)用于每个 NP 事务的完成,详见第 3.3 节。其基本思想是,每个 UIO 写入都有一个完成(C FC 类中的 "UIO 写入完成")。因此,UIO 写入从根本上说是非发布的,即使它是在 P FC 类上,以便让源执行排序。因此,生产者(如图 6(a) 中的设备 X)必须等待所有 "数据 "完成后,才能向 "标志 "写入信号,表示数据可用。UIO 读取就像普通的内存读取一样,它会获得一个或多个完成(C FC 类中的 "UIO 读取完成"),无论是否有数据,都会同时获得状态,包括错误。因此,在 UIO VC 中,P 和 NP 各只有一种类型的事务(分别是 UIO 写和 UIO 读),而 C 有三种类型的事务(UIO 写完成(无数据)、UIO 读完成(有数据)和 UIO 读完成(无数据))。此外,如图 15 所示,跨 FC 和 FC 内部的事务没有排序要求。这样,CXL.io(和 PCIe)事务就能在源-目的对之间具有多条路径的拓扑中的任意路径上发送,并仍然执行生产者-消费者排序语义。VC0 将始终用于传统的非 UIO 排序,以实现路由树拓扑的向后兼容性,VC1-VC7 中的一个或多个 VC 可用于 UIO 流量,UIO 流量可使用任何路径进行任何交易。
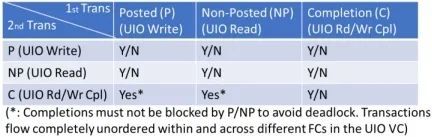
图 15. UIO 排序规则。Y/N "表示第二笔交易可以绕过或不绕过第一笔交易。
CXL 3.0 在 CXL.mem 中引入了带有两个通道的新流程: 如第 5.2 节详细描述的那样,在 S2M 方向上引入了反向无效 (BI),在 M2S 方向上引入了响应 BI-Rsp。这就产生了一种新型设备内存: HDM-DB(Host-managed Device Memory - Device-coherent with Back-invalidate support),由 2 类和 3 类设备支持。
5.3
设备间的对等通信和大块本地内存的映射
CXL 3.0 中的 "反向验证 "流程支持三种使用方式:通过 CXL.io UIO 访问 HDM-DB 内存,实现 CXL/PCIe 设备之间的直接点对点通信(如图 16 所示);第 2 类设备能够实现窥探过滤器,并将大块本地内存映射到 HDM-DB 区域(如图 17(a)所示);跨多个独立主机的硬件强制一致性共享内存(如图 17(b)所示)。在 CXL.mem 中设置 BI 的理由是确保没有其他避免死锁所需的依赖关系。
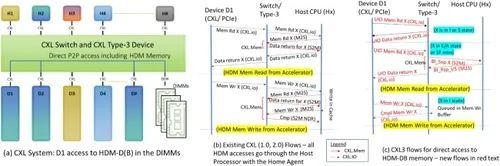
图 16. 利用 UIO 和 BI 优化延迟和带宽的 CXL 3.0 协议增强功能[9]。
利用 UIO 和 BI,设备可以直接访问 HDM-DB 内存,而无需通过主机 CPU。连接到交换机的加速器设备需要访问直接连接到交换机的内存(图 16(a)),该内存映射到 HDM-D 或 HDM-H 区域,使用 CXL 2.0 数据流时需要通过主机 CPU(图 16(b)),这涉及主机从内存获取数据,并在完成设备访问之前解决一致性流。但是,使用 CXL 3.0 流量时,设备会在 UIO VC 中使用 CXL.io 发送相同的内存读写事务。交换机不会将这些 UIO 事务路由到主机。如果高速缓存行的状态为 I 或 S(UIO 读取)或 I(UIO 写入),则 UIO 事务直接由内存提供服务;否则,内存控制器将使用 BI 流反向侦查主机处理器,如图 16(c) 所示。稍后我们将看到,即使在需要 BI 的情况下,这种新机制也比将所有请求发送到主机的现有方法更节省带宽,因为后者会造成更多的流量和额外的延迟。
UIO 与 BI 的结合实现了 I/O 一致性模型,可以扩展到大量设备。那些需要缓存内存的设备在需要时仍可使用 CXL.cache 语义,其他情况下则使用 UIO。这就减少了窥探开销,也减少了一直进入主机处理器的延迟。BI 的第二个方面是让第 2 类设备拥有一个窥探过滤器,而不是拥有一个完整的目录和调用现有的偏置流。图 17(a)演示了这一点,在该图中,如果新请求遇到容量缺失,2 类设备会调用 BI 流程,从其窥探过滤器中驱逐缓存行。
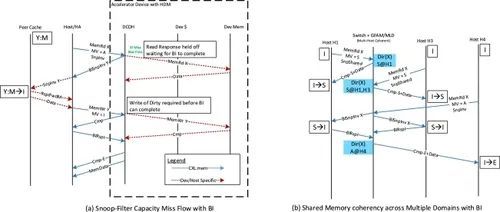
图 17 (a) 现有的偏置-翻转机制需要完全跟踪 HDM,因为设备无法反向窥探主机。CXL 3.0 的 "反向无效 "可实现窥探过滤器,从而产生可映射到 HDM 的大容量内存,(b)CXL 3.0 的 "反向无效 "流程可用于在多个主机之间实现基于硬件的一致性共享内存,每个主机都有独立的一致性域。
如图 17(b)所示,BI 机制还能在多个主机间实现共享和硬件强制的一致性内存。在这里,内存设备(GFD/MLD)维护一个目录(或窥探过滤器),以跟踪一致性共享内存中高速缓存行的所有权。因此,当主机 1 获得作为共享副本的高速缓存行 X 的所有权时,它会将目录从 "I "状态更新为 "S "状态,主机 1 为共享者。当主机 3 请求共享状态下的同一高速缓存行 X 时,它会提供数据并更新 X 的目录,以表明主机 1 和主机 3 都共享该数据。当主机 4 请求独占副本时,它会向主机 H1 和主机 H3 发出 Back Invalidate(回无效),等待两者的响应,以确保主机 1 和主机 3 已将 X 的副本无效,并更新目录,将 X 标记为主机 4 的 "E",然后将数据和所有权发送给主机 4。每个 GFD 可同时支持多达 4,096 个独立节点(MLD 为 32 个)的池式或共享内存,因为每个节点都无法通过配置空间独立发现。
为支持多个独立主机共享一致性内存,设备可在内存中实施片上窥探过滤器和/或目录结构。设备可使用两个位来表示一致性状态(无效、共享、独占),然后是主机共享列表。该列表的实现取决于设备。例如,对于无效状态,列表条目为 "不关心"。对于独占,列表包含独占的主机 ID。对于共享,可以采用位矢量(每个位代表一个或一组主机)或列表的组合方式,其中列表可以识别每个主机,但最多只能识别一定数量的主机,超过这个数量的主机可以粗粒度地表示主机组。实施细节取决于可用的目录位数和可访问缓存行的主机数量。也可以选择在多个高速缓存行(如页面级)中维护窥探过滤器/目录。共享内存的大小和可共享缓存行的主机数量取决于使用模式。例如,大型内存应用,如超大型数据库、日志、机器学习、键值存储、内存分析等。硬件一致性可以扩展这些应用,因为它们大多是只读应用。在某些情况下,可能需要软件一致性。CXL3 架构还支持域间中断、使用共享内存的 Semaphores、数据复制,以及通过共享内存控制器使用特殊地址映射区域进行的消息传递,详情请参见参考文献[9, 18]。
反向验证在协议层和链路层创建了两个额外通道: BISnp 和 BIRsp。与图 10(b) 中的 CXL 1.1/CXL 2.0 依赖关系图相比,图 18 所示的更新依赖关系图中增加了 BISnp(S2M BISnp),这些通道是确保协议无死锁所必需的。BIRsp 已预先分配,因此在依赖关系图中,它被合并到图中的 L3 RSP 中。
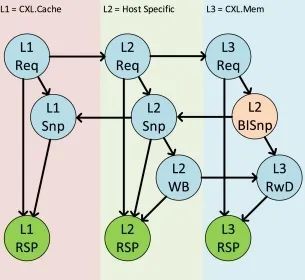
图 18. 更新后的 CXL 3.0 协议依赖性与反向验证。
5.4
CXL.cache 设备扩展
在 CXL 3.0 之前,每个虚拟层次结构只能支持一个 CXL.cache 设备。为支持更多设备,报文中增加了一个 4 位 ID 空间 "CacheID",使每个根端口最多可支持 16 个 CXL.cache 设备。主机要支持 CXL.cache,就必须拥有窥探过滤器结构,以跟踪设备可能缓存的每个地址。主机中这种跟踪的大小将限制设备缓存主机内存的能力,因此主机中的大小将限制设备可以缓存多少主机数据。请注意,对于 2 类设备,主机不会限制设备缓存自身内存的能力。增加 CacheID 后,主机必须单独跟踪根端口后面的每个设备,以避免退化为多播窥探行为。多播窥探功能是可行的,但不能满足带宽/性能要求,即设备应很少看到不在设备缓存中的地址窥探。主机一致性跟踪的限制可能会限制可支持的 CXL.cache 设备总数。主机将在主机网桥粒度上公布这一限制。软件可发现这一功能,并在枚举 CXL 层次结构时强制执行这一限制。
5.5
端口基础路由(PBR)和 CXL Fabric 扩展
为了将端点(主机或设备)和非树(多路径)网络拓扑扩展到 4,096 个,CXL 3.0 增加了一种新的可选协议格式,称为端口基础路由(PBR)。与 CXL 2.0 的分层路由(第 4.1 节)相比,PBR 的理念是只关注 PBR 交换机之间路由信息所需的信息,因此是一种更简单、更可扩展的协议。例如,分层路由要求交换机知道虚拟分层和每台主机的地址映射。CXL 3.0 在大多数端点与第一个交换机之间的链路中继续使用标准 CXL 2.0 信息(如图 12 中的叶子到端点链路)。连接设备或主机的第一个交换机端口被称为 "边缘端口",因为它在标准报文(HBR)和 PBR 报文之间的转换中起着特殊作用。PBR 路由本身用于交换机间链路,如图 12 中的 Spline 到 Spline 和 Leaf 到 Spline 链路)。从软件角度看,只有 Fabric 管理员需要配置交换机网络;在主机上运行的软件看到的只是一个以第一个交换机端口为终点的平面拓扑。
PBR 使用 12 位 ID(称为 PBR-ID (PID))对端点进行寻址。边缘端口将此标识符添加到报文中,作为目的 PID(DPID),有时也作为源 PID(SPID)。PID 的生成是通过使用各种方法将 HBR 报文转换/解码为 PBR 报文完成的。这种转换是无状态的,即不需要跟踪任何未处理的请求。这种转换的例子包括地址到 PID、LD-ID 到 PID/从 PID、CacheID 到 PID/从 PID、总线编号到 PID/从 PID。对于从 LD-ID 到 PID 的转换,PID 提供的位数较少,可通过一个 16 位的查找表来解决,该查找表以 4 位 LD-ID 为索引,用于确定主机的 PID。在 "地址转 PID "的情况下,这是通过解码主机物理地址 (HPA) 和查找 Fabric 地址段表 (FAST) 来实现的。为了提高可扩展性,FAST 为每个 PID 提供了一个 2 次幂大小的单一内存范围,这样就可以直接使用可选地址位来查找拥有 HPA 区域的 PID。由于 HBR 信息与 PBR 信息之间的转换是由边缘端口透明执行的,因此主机和设备可以在不直接感知 PBR 的情况下使用 PBR。此外,由于地址解码已在边缘端口完成,内部 PBR 交换机(如图 12 中的 Spline 交换机)可以纯粹根据 DPID 路由报文,而无需执行地址解码。如果不进行这种简化,多个虚拟层次结构共享的中间链路就需要为共享链路的所有虚拟层次结构(VH)提供完整的地址解码功能,从而限制了 VH 的数量。因此,PBR 可以提高可扩展性,减少内部交换机的延迟和成本。
PBR 信息的路由由 Fabric Manager (FM) 集中控制(第 4.2 节)。FM 为每个 PBR 交换机配置一个以 12 位 DPID 为索引的查找表。这些表将 DPID 映射到交换机的出站物理端口。为实现多路径路由,查找表可提供多个目标物理端口,在这些端口上,无序流量可根据负载情况动态路由到目标端口。对于 CXL.io,UIO VC 是完全无序的,可以通过流量到达的 VC 轻松识别。CXL.cache-mem主要是无序的,但有一些有限的排序例外规则,用于解决冲突(例如:在CXL.Cache Snoops中,将GO推送到相同的地址);通过确保排序信息遵循相同的路径,适当地交错,即使有多条路径,也能轻松执行这些例外规则。例如,CXL.mem 非数据响应通道中的标签位可用于交错,因为只有具有相同标签的报文才需要排序。传统 CXL.io 等有序流量的灵活性较低,因为必须始终选择相同的单一路径,这符合所有链路的树状拓扑结构。当 FM 发现链路或交换机故障时,它还可以重新配置路由表,并将新的查找表重新分配给 PBR 交换机。
交换机间链路(ISL)携带 PBR 信息格式。这些链路在性质上也是对称的,因为它们可以在同一链路上以相反的方向承载来自不同主机的上行和下行流量。具体来说,非 PBR 端口支持 6 个上行 CXL 通道和 6 个下行 CXL 通道。PBR 端口必须能分别承载 12 个上行和下行 CXL 通道。支持 ISL 要求底层高速缓存和内存链路层提供一组完全对称的通道,每个通道都有自己的流量控制信用。这与设备和主机链路不同,它们要么是上游链路,要么是下游链路(主机到交换机是下游链路,设备到交换机是上游链路)、
内存设备也可以直接参与 PBR,而不是依赖边缘端口。这种端点被称为全局 Fabric 附加内存设备(GFD)。在 CXL 2.0 多逻辑设备(MLD)最多只能由 16 台主机共享的情况下,GFD 允许在 CXL Fabric 中的所有 4095 个其他代理之间共享/池化高扩展性内存设备。
6
CXL 实施情况调查
CXL 生态系统需要 CPU 和设备的支持。虽然 CXL 3.0 产品预计将在几年内推出,但 CXL 1.1 和 CXL 2.0 已部署在多个商用产品中。英特尔从蓝宝石激流(SPR)CPU 和 Agilex7 FPGA 开始支持 CXL,支持所有三种协议。AMD 在 Genoa 和 Bergamo CPU 中支持 CXL,并宣布支持 SmartNIC 设备 [50];ARM 宣布在 V2、N2 和 E2 系列 CPU 中支持 CXL 2.0 [55]。
在设备方面,Synopsys、Cadence、PLDA/Rambus、Mobiveil 等 IP 供应商已经展示了与 SPR CPU 的互操作性 [8、21、22]。三星制造了一个 CXL 1.1 内存扩展设备,并公开分享了其基准测试结果[52]。Montage[53]、SK Hynix[54]、Microchip[77]、Micron[75]和 Astera Labs[76] 发布了 CXL Type 3 存储器设备。美光公司已经推出了 CXL 1.1 近内存计算设备的原型[51]。学术研究也独立复制了 SPR [48] 上的结果,并实现了定制的 CXL 硬件和软件原型 [49]。
在接下来的章节中,我们将报告 CXL 实现的测量结果。我们在多个设备供应商的英特尔和 AMD CPU 上测试了 CXL.mem。不过,由于公开的性能数据主要针对英特尔 CPU,因此我们的调查主要侧重于英特尔实现的性能,以此作为 CXL 实现的代表性性能指标。
图 19 是具有代表性的 CXL IP 微体系结构,其中包括 PIPE [23]、LPIF [24]、CPI [25] 和 SFI [26] 等用于 CXL 端点和 SPR 等主机处理器的行业标准接口。图 10(a)中的内存大小、高速缓存层次结构和高速缓存大小只是提供了一个比例,而不是精确的大小。最后一级高速缓存(LLC)包括层次结构中的低级高速缓存以及与 CPU 内部 PCIe/ CXL.io 堆栈相关的写高速缓存。LLC 还覆盖所有 CXL 设备的缓存。窥探过滤器为主代理提供了何时窥探特定 CXL 设备的信息。无论是与 CPU 本地连接的内存(如 DDR),还是属于映射到系统地址空间的 CXL 设备的内存,都属于主代理的权限范围(图 10(a) 中用蓝色和绿色表示)。
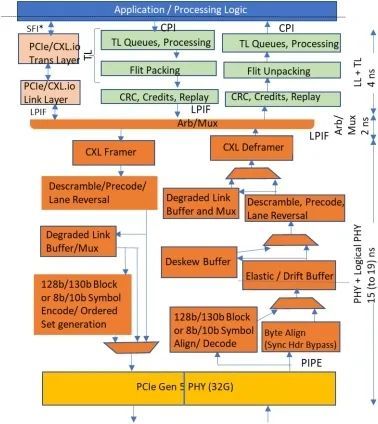
图 19. 具有代表性的微体系结构与 CXL 微体系结构的典型延迟[8]。
6.1
CXL 1.1 实现的实测延迟
从高层来看,CXL 延迟由协议部分和队列部分组成,队列部分取决于负载。我们首先关注空闲系统中的 CXL 协议延迟。图 19 显示了不同 CXL 块在英特尔 SPR 上的延迟明细。PHY 模块显示了负责数据序列化/反序列化的模拟电路。它通过 PIPE 的并行接口连接到 PHY 逻辑块(32 位,每列 1 GHz,32.0 GT/s 链路)。物理层逻辑模块还执行链路训练、均衡、(去)扰码、预编码、线路反转、链路宽度衰减、极性反转、时钟域交叉、时钟补偿、去歪斜和物理层成帧。
LPIF 芯片到芯片接口[24] 将物理层逻辑连接到 Arb/Mux 模块,再从 Arb/Mux 模块连接到多个链路层。Arb/Mux 块在两个堆栈(CXL.io 和 CXL.cache+mem;见第 3.2 节)之间执行仲裁和多路复用,并将物理层虚拟化为独立的链路层堆栈,以进行电源管理 [1,2,3,8]。
链路层(LL)(如图 19 所示)执行 CRC 校验、管理积分和处理链路层重试,而事务层(TL)则执行 Flit 打包/拆包、将事务存储在适当的队列中并处理事务。在 CXL 3.0 实现中,当协商 256 字节或 128 字节延迟优化 Flit 时,逻辑物理层将执行所有堆栈通用的 CRC 和重放功能,而每个堆栈的链路层将继续提供相同的功能,但仅限于该堆栈的 68 字节 Flit 模式,以实现向后兼容性。CXL.io/PCIe 事务层对事务进行排队、处理并执行生产者-消费者排序[8]。
图 19 适用于 CXL.cache+mem 路径,包括发送和接收路径。与标准 PCIe 物理层逻辑实现相比,多种优化措施改善了延迟。这些优化包括绕过 128 b/130 b 编码(如果在链路培训期间协商好[3]),绕过支持降级模式所需的逻辑和串行化触发器(如果一个或多个车道出现问题,或者如果为电源管理而调用),如果车道到车道偏移小于内部 PHY 逻辑时钟周期的一半,则绕过纠偏缓冲器,采用预测策略处理弹性缓冲器中的条目(而不是等待每个条目的时钟域同步握手),等等。PHY 和 PHY 逻辑延迟的不同取决于部署的是通用参考时钟还是独立参考时钟。如果组件都在单个机箱内,那么我们期望使用一个延迟为 15 纳秒的通用参考时钟。但是,如果链路跨机箱连接,那么我们预计独立参考时钟会因时钟交叉和同步 Hdr 开销而造成 4 纳秒的延迟损失。
在通用参考时钟模式下,从 SERDES 引脚到内部应用层(CPI 或等效接口)再返回的总延迟为 21 纳秒,在独立参考时钟模式下为 25 纳秒。一家 IP 供应商也报告了 25 ns 的往返延迟[15]。由于各种区块的位置、工艺技术和物理层设计类型造成的传播延迟等因素,预计在不同的实现中会出现微小的延迟差异。例如,与基于 DFE/CTLE(决策反馈均衡器/连续时间线性均衡器)的接收器设计相比,现有的基于 ADC(模数转换器)的 PHY 可能会增加约 5 ns 的延迟。
CXL 端口的 21-25 纳秒往返延迟会在 CXL.cache+mem 设备访问时发生两次,一次在 CPU 上,一次在设备上。此外,我们估计使用重定时器的往返飞行时间为 15 纳秒[17,18]。这样,通过 CXL 链路访问内存的端到端延迟加法为 57 纳秒。因此,即使存在设计上的差异,CXL 规范中针对 DRAM/ HBM 存储器的 CXL.mem 存取的引脚到引脚延迟目标为 80 纳秒,窥探的响应时间为 50 纳秒[3,4,6]。这种加法器与通过 CPU-CPU 缓存相干链路进行的内存访问相当,而且完全符合 CPU 的延迟工作点 [20]。对于 CXL.io,与 PCIe 中一样,在 Xeon 中从引脚到引脚的往返延迟为 275 ns(LLC 未命中和 IOTLB 命中)。
我们进行的端到端测量涵盖了包括队列在内的所有 CXL 开销。由于队列延迟是负载和系统容量的函数[19],图 20 显示了后台内存带宽负载增加时的平均内存访问延迟。这项测量是在英特尔 EMR 系统上进行的,该系统配备了两个试生产的 Astera Labs Leo CXL 智能内存控制器[76],每个控制器有 x16 个 CXL 通道。所有通道都装有单个 64 GB DDR5-5600 DIMM。这里显示的工作负载组合包括每写两次读取(2R1W)。我们首先比较了 CXL 与本地 DDR5 和跨插槽(UPI)DDR5 访问的延迟,在这三种情况下,我们都配置了四个内存通道(图 20(a))。低负载时,CXL.mem(蓝线)的延迟约为本地 DDR5 访问(橙线)的 200%-220%,与跨 UPI 访问远程 DDR5 的延迟相当(图 20(a)中的绿线)。此外,值得注意的是,本地 DDR5 和 CXL 上连接的 DDR5 的延迟曲线斜率非常相似。来自利奥 CXL 智能内存控制器的 x32 组合 CXL 通道的峰值内存带宽最大约为 137 GB/s,充分利用了 CXL 通道,并与四个本地 DDR5 通道相匹配。CXL 实现的带宽约为通过 UPI 访问远程 DDR5 的 1.5 倍。
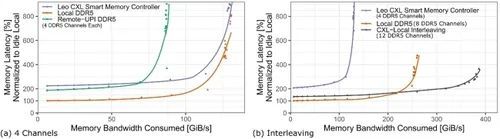
图 20. 相同数量的四个 DDR 通道(a)以及典型通道配置中的本地、CXL 和交错内存(b)的内存访问延迟与带宽负载的函数关系。图中线条采用局部回归法[82]进行平滑处理。
图 20(b)显示了四通道的 CXL(蓝线)、八通道的本地 DDR5(橙线)以及本地 DDR5 和 CXL 内存交错访问的配置(深灰色线)。与仅使用本地 DDR5 相比,交错使用本地和 CXL 可提供 1.5 倍的峰值内存带宽,有效地结合了 CXL 和本地 DDR5 带宽。在带宽负载超过 200 GB/s 时,与仅使用本地 DDR5 相比,交错可显著降低负载和队列。这表明,交错使用本地内存和 CXL 内存对带宽密集型应用很有吸引力。对于延迟敏感型应用,另一种方法是硬件分层,如英特尔扁平内存模式[80]。
6.2
采用 CXL 3.0 及更高版本的
大型系统拓扑的预计延迟
采用 CXL 的大型拓扑结构可通过交换机以及共享内存控制器(SMC)等设备实现,共享内存控制器是 CXL 交换机与多个内存控制器的组合[9, 18](图 16(a)),具有多域功能和 PBR 路由功能,可用于扩展。CXL 交换机与往返的延迟加法器预计为 2x21-25+10 ns 内部 arb/look-up+10 ns 线上飞行时间 = 62-70 ns [18,56]。表 2 总结了不同访问/系统配置下 CXL.cache 和 CXL.mem 的各种延迟。
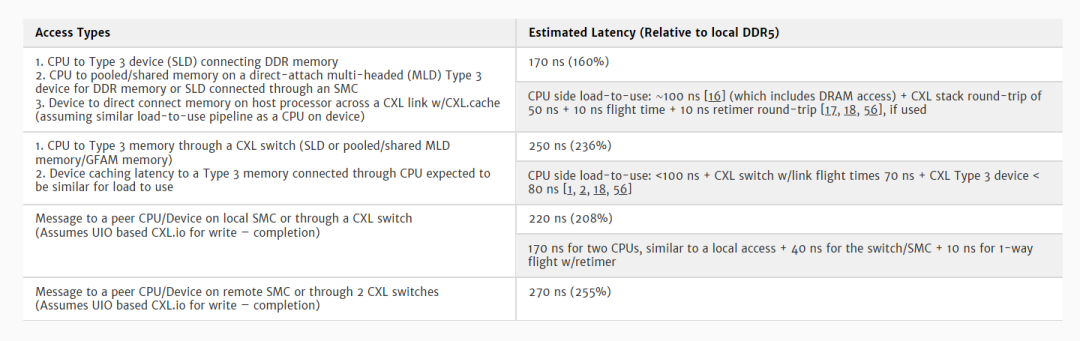
表 2. 各种拓扑结构下 CXL.cache 和 CXL.mem 的估计延迟 [10]
6.3
可实现的数据带宽
x16 CXL 链路在 32.0 (64.0) GT/s 数据速率下,每个方向的原始带宽为 64 (128) GB/s。但是,除了实际有效载荷(包括报头、CRC 和协议 ID/Flit HDR)外,链路传输数据还会产生协议开销(见第 3.2 节)。此外,不同的工作负载会产生不同的请求和响应模式,对 Flit 插槽的占用也不尽相同。因此,可实现的数据带宽是由工作负载、协议和底层 IP 之间的多层交互决定的。我们首先讨论三种协议(CXL.io、CXL.cache 和 CXL.mem)的共同开销,然后讨论常见流量组合下的可实现数据带宽。
对于 68 字节 Flit 模式下的 CXL.io,假设 DLLP 开销为 2%,在同步 Hdr 开启或关闭的情况下,链路效率分别为 0.906 和 0.92[8]。请注意,本地 PCIe 的效率要高出 6%,因为 PCIe 不包含 Flit 开销。对于使用 256 B 和 128 B LO Flits 的 CXL.io,Flit 开销为 6 B(Hdr、DLLP)+ 6 B(FEC)+ 8 B(256 B)/12 B(128 B LO)(用于 CRC)[10,11]。256 B Flit 的总开销为 20 B,128 B LO Flit 的总开销为 24 B,链路效率分别为 0.92 和 0.91 [8,9]。
68 字节 Flit 模式(CXL 1.1-2.0)下的 CXL.cache+mem 有三个常见开销: 128/130 表示同步 Hdr 开销(除非支持同步 Hdr 旁路),374/375 表示公共时钟 SKP 有序集造成的带宽损耗(其他模式更高),64/68 表示 Flit 开销(协议 ID 和 Flit CRC 各 2 字节)。因此,同步 Hdr 开启时的链路效率为 0.924,同步 Hdr 关闭时的链路效率为 0.939。这包括积分和链路可靠性机制,如 Ack/Nak(Ack:确认,Nak:负确认)[8]。
对于 CXL.cache 和 CXL.mem 的 256 字节和 128 字节 Latency-Optimized (128 B LO) Flits,整体链路效率为 15/16 (=0.938),因为有 15 个时隙,一个等效时隙用于 FEC/ CRC/ Hdr 等 [8,9]。CXL.cache 和 CXL.mem 的插槽数量相差无几,即使考虑到可扩展性所需的额外位数。因此,正如下文所述,三种 Flit 类型的带宽效率往往相似。
在 CXL.io 和 PCIe 中,有三种常见的流量组合可作为性能基准:100% 读取、100% 写入和 50-50 读写。表 3 根据参考文献[8]中描述的方法,总结了三种流量组合中每种流量大小、每种 Flit 类型的 CXL.io 带宽。典型的工作负载包括小型有效载荷(4 B-32 B)和中大型有效载荷(64 B 及以上)的混合。尽管商用系统为客户端 CPU 部署的最大有效载荷大小为 128 B(或 32 双字,又称 DW),为服务器 CPU 部署的最大有效载荷大小为 256 B/512 B(64/128 DW),但为了完整起见,我们还是提供了最大 4 KB(1,024 DW)有效载荷大小的预测值。
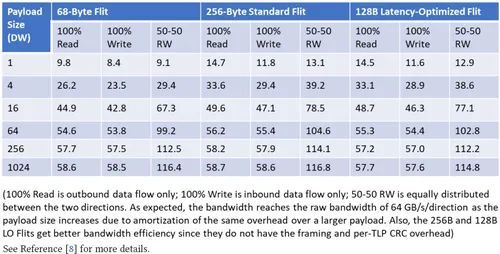
表 3. CXL.io 以 GB/s 为单位的可实现带宽,适用于不同流量混合和有效载荷大小的 CXL 2.0 68 B Flits 和 CXL 3.0 256 B 和 128 B Flits x16 链路,速度为 32 GT/s
CXL.cache: 设备使用 D2H 中的 RdCurr 从内存读取高速缓存行时,会产生一个 H2D Data_Hdr 和 H2D Data。每个 H2D Data_Hdr 为 24 位,一个插槽中可容纳 4 个,即一个插槽中可传输 4 个高速缓存行。每个 H2D 数据为 64 字节,因此需要 4 个插槽。因此,x16 CXL 设备从处理器读取 68 字节 Flit 格式的数据时,可获得 (16/17) *0.94*64 GB/s = 56.6 GB/s 的带宽。对于 256 字节和 128 字节延迟优化的 Flits,数据是瓶颈,因为每个 H 插槽最多可以有 4 个 H2D Data_Hdr。对于 256 字节的 Flit,我们只有 14 个插槽可用于数据,可容纳 3.5 个高速缓存行。因此,256 字节 Flit 的可实现带宽为:(14/16) *128=112 GB/s;128 字节延迟优化 Flit 的可实现带宽为:(13/16) *128=104 GB/s[8,9]。
对于写入,设备会发出 D2H 请求 (RdOwn)。这将产生一个带数据的 H2D 响应。然后,设备发出 D2H Dirty Evict,获得 H2D Resp (Wr Pull),从而执行 D2H Mem Wr。这样,D2H 方向上每一行缓存数据就会产生 3 个 Hdr(D2H Req RdOwn、D2H Dirty Evict + Data Hdr)。对于 68 字节的 Flit,3 个 Hdrs 占用两个插槽(如 D2H Req RdOwn+ Data Hdr、D2H Dirty Evict),因此每个方向的速度为 (4/6) *0.94*64 GB/s = 40 GB/s。对于 256 字节和 128 字节延迟优化的 Flit 格式,D2H 方向有 4 个 G 插槽和 2.25 个任意插槽(Req 和 Evict Dirty 插槽各一个,Data_Hdr 插槽为 ¼,因为任意插槽中可以有 4 个),因此可实现的数据带宽为(4 个数据插槽/6.5 个总插槽)*(15/16)*128 = 73.8 GB/s[8,9]。
CXL.mem: 在 M2S(第 3.5 节)中,CPU 的内存读取作为 MemRd 发送。对于 3 型设备,其响应包括 S2M DRS Hdr (MemData) 和 4 个数据插槽 (64B)。如果设备是 2 类设备,则需要额外的 S2M NDR 以完成 (Cmp)。对于写入,CPU 发送 M2S Req (MemWrite) 和 4 个数据插槽,生成 S2M NDR 作为 Cmp。
实施过程中,CPU 会尝试在一个插槽中打包多个标头,以最大限度地提高效率。CXL 规范允许在一个插槽中对各种标头进行不同的打包排列,这些排列使用所谓的 H* 符号表示 [8]。
有几种具有代表性的工作负载可用于评估内存带宽性能。100% 读取,表示为 1R0W;100% 写入,表示为 1R1W,因为每个高速缓存行的写入都会在更新前读取内存内容;等量读写,表示每写入一个高速缓存行就会读取两个高速缓存行。表 4 总结了不同流量组合下 CXL.mem 的可实现带宽。详细推导见参考文献[8]。当只有读取而没有写入时,M2S 方向上没有真正的数据传输(只有读取请求)。因此,该方向的数据带宽为 0,而 S2M 方向则主要是数据(2DRS 有 1 个数据头插槽,2 个高速缓存行有 8 个数据插槽)。因此,数据效率为:链路效率 0.939 x 插槽效率 8/9 x 64 GB/s 原始带宽 = 53.5 GB/s。其他条目也采用类似方法,详见参考文献[8]。SPR Flit 包装逻辑中的调度程序遵循 CXL.mem 的贪婪算法,优先处理 Flit 中第一个 16 B 插槽的 H3,然后是 H5,如果计划发送的数据少于 64 字节,则在其余 Flit 中填充数据。如果计划发送 64 字节或更多数据,则会调度一个全数据 Flit。采用这种方法后,68-B Flit 模式的测量带宽与表 4 中的数字非常接近。
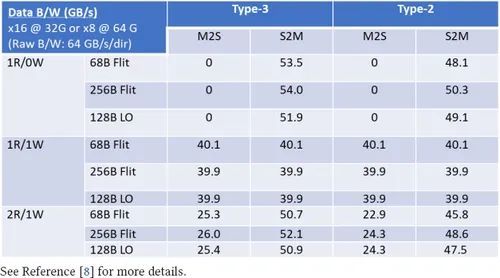
表 4. 对于速度为 32 GT/s 的 x16 链路,CXL.mem 在 CXL 2.0 68 B Flits 和 CXL 3.0 256 B 和 128 B Flits 不同流量混合情况下的可实现带宽(GB/s)。
对于 256 字节标准或 128 字节延迟优化 Flit,设计人员需要考虑额外的限制。例如,H/HS 插槽可能只用于数据头。调度将确保在有数据(或报头)要发送时,G 槽不会空着。因此,先于数据发送的报头将被优先考虑,并择机放置在 H/HS 插槽中,同时确保调度的数据不超过 5 个高速缓存行。我们还确保其他报头向前推进。
利用 CXL 3.0 [6, 8, 9]中引入的 UIO/BI 流量,可以绕过主机处理器,使用 CXL.io UIO 流量在设备间直接进行访问,既可用于 HDM 访问,也可用于不需要缓存的域间消息。由于 I/O 设备和内核通常不会同时访问相同的数据,因此绝大多数情况下都不会调用 BI-Snp 机制来执行一致性。这有助于提高链路效率,缓解主机-处理器链路的拥塞问题。在表 5 的分析中,即使在 100% 的访问都会导致 BI-Snp 的病理情况下(表 1b 中的 x =1.0 情况),该机制的效率提升也非常显著。这种从主机和设备同时进行的访问可能发生在用于同步的控制数据结构上。通常情况下,我们会将此类数据结构置于主机内存中。不过,即使 100% 的访问都会导致 BI-Snp,UIO/BI 也比跨链路的多缓存行传输要好。
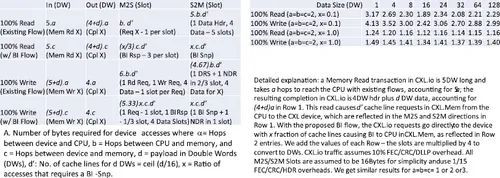
表 5. 反向验证(BI)和无序 IO(UIO)流的链接效率 [9]
7
讨论
我们将讨论 CXL 对计算领域的四种影响,然后概述一系列初步的未来发展方向。
7.1
对计算领域的影响
影响 1:CXL 对设备的网络效应。与 PCIe 相比,CXL 显著扩展了使用模式和功能,例如,延迟更低、池化和硬件一致性。这些优势促使 I/O 设备采用 CXL。最初,这可能最适用于加速器和内存/存储设备,因为CXL.cache和CXL.mem可带来巨大的性能提升,而CXL池可节省总体拥有成本。最终,CXL 的采用可能会产生网络效应,网络接口等其他 IO 设备必须提供 CXL,因为 CXL 将成为通用访问机制。同样,近内存或内存处理系统也可能采用 CXL,因为 CXL 对高速缓存一致性的强大支持大大简化了编程模型。
影响 2:内存向封装内并行总线和封装外 CXL 迁移。与本地连接内存(DDR)相比,CXL 具有基本的扩展和效率优势。CXL 的每引脚带宽高出 8 倍,容量也更大,因此具有显著的可扩展性优势。内存池和异构内存介质使 CXL 具有成本优势 [56]。CXL 还有助于散热,因为与 DDR 相比,它能实现更长、更灵活的主板布线。这些优势是以高于 DDR 的空闲延迟(通常是 DDR 延迟的两倍)为代价的。在考虑加载延迟时,CXL 因其带宽优势可能比 DDR 性能更好,而封装内内存的性能将明显优于两者。一个自然的预期是,将有更多内存迁移到 CXL 和封装内存。最终,CXL 将成为 CPU 和加速器的唯一外部内存连接点。
影响 3:CXL 将发展成为机架或集群级互连。与当今基于以太网和 InfiniBand 的数据中心网络相比,CXL 可将延迟降低一个数量级。此外,CXL 的连贯内存共享和细粒度同步可显著提高分布式系统的性能,适用于大型机器学习模型和数据库等关键工作负载。不过,CXL 需要专用布线,对电缆长度、适配器和重定时器的使用等有严格要求。这导致成本大大增加,灵活性也比现在的数据中心网络低。因此,CXL 有可能部署在较小的范围内,如机架内或跨几个机架(集群或 pod)。例如,当前的财务模型指出,子机架 CXL 部署是总体拥有成本的甜蜜点[56]。随着标准化带来的成本改善,CXL 的应用范围可能会扩大,但 CXL 不太可能取代以太网成为整个数据中心的网络标准。
影响 4:CXL 将实现高度可组合系统。可组合性意味着可在运行时动态组装组件和资源,并将其分配给工作负载或虚拟机。我们预计,内存设备和 IO 设备(如网卡、加速器和存储设备)都将发展出多主机功能,允许通过 CXL 将其容量的一部分动态分配给各个主机。由于多路复用机会增加,聚合和池化设备可显著提高资源利用率,从而降低成本。这种设计还有利于通过共享内存、消息传递和 CXL 点对点通信加速分布式系统。不过,可组合系统仍有别于将通过 CXL 连接的所有资源视为一个单一的大系统。工作负载仍然倾向于本地化,并尽可能少地跨越 CXL 链接,以最大限度地减少一致性流量和任何故障的爆炸半径。
7.2
未来方向
CXL 开启了计算机科学与工程领域的研究方向。在计算机体系结构中,CXL 为新内存控制器功能的原型设计和部署开辟了道路[59],例如自适应 DRAM 刷新以节省功耗和提高性能[60, 61],低成本提高可靠性[62],以及减少内存浪费[63, 64]。外部存储器控制器的发展可以独立于主 CPU,而且成本较低,有利于加快迭代和定制。研究还可探讨对 CPU 架构的影响。例如,随着更高的内存延迟和更多的飞行高速缓存线,人们可能会期待不同的预取和缓冲区大小策略,以及对减少内存访问延迟的更大兴趣[67, 68]。另一个挑战可能是延迟命中的影响,这需要更严格的模拟和建模[58]以及不同的高速缓存管理策略[57]。
在计算机系统中,CXL 内存池将引发本地和分布式内存管理的变革。例如,面对来自远程主机的内存压力,我们需要能确定工作负载优先级并保证性能的机制。我们可能还需要系统级方法来缓解分布式内存结构中的拥塞和故障。例如,CXL 标准中的 QoS 目前仅限于 CXL.mem,无法解决结构拥塞问题。工作负载调度也需要发展,以支持可组合性,与现有的数据中心设计相比,设计空间大幅扩大,位置定义也有所不同。CXL 规范需要不断发展,以提供跨其他协议的 QoS,同时处理 Fabric 拥塞,并在事务级支持动态多路径,以实现 QoS 和故障转移。
在计算机工程领域,研发工作需要继续降低 CXL 内存、加速器和交换机的延迟,以扩大 CXL 的适用性。现在有很多机会,包括迭代工程 CXL 构建模块、利用工艺进步(第 6.1 节)和更好的打包算法(第 6.3 节)。生态系统还需要制定严格的方法来控制误差和管理 CXL 增加的爆炸半径。使用负载存储语义处理故障和拥塞热点与网络应用有着不同的限制,后者可以处理丢失的数据包以及完全失序的数据包交付。最后,CXL 可以进一步增强和部署,以扩展到多个机架,并通过动态故障切换和更细粒度的 QoS 增强功能为多个应用提供高可靠性和低延迟的负载存储访问,这些功能将纳入未来的规范修订中。通过通用片式互连快车(UCIe)重定时器[10、48、72、73、74]实现的协同封装光学技术,我们有望实现在数据中心构建从机架到 pod 的可组合和可扩展系统的愿景,从而实现具有显著总体拥有成本优势的高能效性能。
8
结论
CXL 解决了行业面临的重大挑战,同时遵循基于开放性、简易性和向后兼容性的设计理念。这使得 CXL 成为整个行业的通用标准。所有这些因素使得 CXL 在学术界也成为一个热门研究领域。我们希望本教程既能作为标准的介绍和起点,也能作为研究思路的基础。
参考文献
[1]D. Das Sharma. 2019. Compute Express Link. White paper. In Compute Express Link Consortium.
[2]Compute Express Link Consortium, Inc. 2019. Compute Express Link 1.1 specification.
[3]Compute Express Link Consortium, Inc. 2020. Compute Express Link 2.0 specification.
[4]D. Das Sharma and S. Tavallaei. 2020. Compute Express LinkTM 2.0. White paper. In CXL Consortium.
[5]Compute Express Link Consortium, Inc. 2022. Compute Express Link 3.0 specification. Retrieved from www.computeexpresslink.org
[6]D. Das Sharma and I. Agarwal. 2022. Compute Express Link 3.0. White paper. In CXL Consortium.
[7]PCI-SIG. 2022. PCI Express® base specification revision 6.0, Version 1.0.
[8]D. Das Sharma. 2023. Compute Express Link®: Enabling heterogeneous data-centric computing with heterogeneous memory hierarchy. IEEE Micro. (2023 Mar.–Apr).
[9]D. Das Sharma. 2023. Novel composable and scale-out architectures using Compute Express LinkTM. IEEE Micro. 29 (Mar.–Apr. 2023).
[10]D. Das Sharma. 2022. Transforming the data-centric world. In Flash Memory Summit.
[11]D. Das Sharma. 2021. Evolution of interconnects and fabrics to support future compute infrastructure. In Open Fabrics Alliance Workshop.
[12]D. Das Sharma. 2021. The Compute Express Link (CXL)* open standard is changing the game for cloud computing. In IEEE Hot Interconnects Conference.
[13]D. Das Sharma. 2022. A low-latency and low-power approach for coherency and memory protocols on PCI Express 6.0 PHY at 64.0 GT/s with PAM-4 signaling. IEEE Micro. (2022 Mar.–Apr).
[14]D. Das Sharma. 2021. PCI Express 6.0 specification: A low-latency, high-bandwidth, high-reliability, and cost-effective interconnect with 64.0 GT/s PAM-4 signaling. IEEE Micro (2021 Jan.–Feb).
[15]Stephane Hauradou. 2020. Rambus Webinar. https://www.brighttalk.com/webcast/18357/420129
[16]Microchip Inc. 2020. XpressConnectTM PCIe® Gen 5 and CXLTM Retimer Family. https://iotdesignpro.com/sites/default/files/component_datasheet/XpressConnect-PCIe-Retimers-Datasheet.pdf
[17]Hasan Al Maruf, Hao Wang, Abhishek Dhanotia, Johannes Weiner, Niket Agarwal, Pallab Bhattacharya, Chris Petersen, Mosharaf Chowdhury, Shobhit Kanaujia, and Prakash Chauhan. 2022. TPP: Transparent Page Placement for CXL-enabled tiered memory. In (ASPLOS'23).
[18]Huaicheng Li, Daniel S. Berger, Lisa Hsu, Daniel Ernst, Pantea Zardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D. Hill, Marcus Fontoura, and Ricardo Bianchini. 2023. Pond: CXL-based memory pooling systems for cloud platforms. In ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS’23).
[19]Mor Harchol-Balter. 2013. Performance Modeling and Design of Computer Systems: Queueing Theory in Action. Cambridge University Press.
[20]Kevin Lim et al. 2009. Disaggregated memory for expansion and sharing in blade servers. ACM SIGARCH Comput. Archit. News 37, 3 (2009), 267–278.
[21]Synopsys Inc, Retrieved from https://news.synopsys.com/2020-10-13-Synopsys-Demonstrates-Industrys-First-PCI-Express-5-0-IP-Interoperability-with-Intels-Future-Xeon-Scalable-Processor
[22]Mobiveil, Retrieved from https://www.globenewswire.com/news-release/2020/12/02/2138545/0/en/Mobiveil-Announces-Compute-Express-Link-CXL-2-0-Design-IP-Successful-Completion-of-CXL-1-1-Validation-with-Intel-s-CXL-Host-Platform.html
[23]Intel Corporation. 2019. PHY Interface for the PCI Express, SATA, USB 3.1, Display Port, and Converged I/O Architectures. Version 5.1. https://www.intel.com/content/dam/www/public/us/en/documents/white-papers/phy-interface-pci-express-sata-usb30-architectures-3.1.pdf
[24]Intel Corporation. 2019. Logical PHY Interface (LPIF) Specification. Version 1.0. https://www.intel.com/content/dam/www/public/us/en/documents/technical-specifications/lpif-adapter-white-paper.pdf
[25]Intel Corporation. 2020. CXL-Cache/Mem Protocol Interface (CPI). Rev 0.7. https://www.intel.com/content/www/us/en/content-details/644330/compute-express-link-cxl-cache-mem-protocol-interface-cpi-specification.html
[26]Intel Corporation. 2020. Streaming Fabric Interface (SFI). Rev 0.7. https://www.intel.com/content/www/us/en/content-details/644200/streaming-fabric-interface-sfi-specification.html
[27]Jing Guo, Zihao Chang, Sa Wang, Haiyang Ding, Yihui Feng, Liang Mao, and Yungang Bao. 2019. Who limits the resource efficiency of my datacenter: An analysis of Alibaba datacenter traces. In International Symposium on Quality of Service.
[28]Muhammad Tirmazi, Adam Barker, Nan Deng, Md. E. Haque, Zhijing Gene Qin, Steven Hand, Mor Harchol-Balter, and John Wilkes. 2020. Borg: the next generation. In 15th European Conference on Computer Systems.
[29]Eli Cortez, Anand Bonde, Alexandre Muzio, Mark Russinovich, Marcus Fontoura, and Ricardo Bianchini. 2017. Resource central: Understanding and predicting workloads for improved resource management in large cloud platforms. In 26th Symposium on Operating Systems Principles.
[30]Qizhen Zhang, Philip A. Bernstein, Daniel S. Berger, and Badrish Chandramouli. 2021. Redy: Remote dynamic memory cache. VLDB J. 15, 4 (2021), 766–779.
[31]J. Gu, Y. Lee, Y. Zhang, M. Chowdhury, and K. G. Shin. 2017. Efficient memory disaggregation with INFINISWAP. In USENIX Symposium on Networked Systems Design and Implementation (NSDI’22). 649–667.
[32]Huan Liu. 2011. A measurement study of server utilization in public clouds. In IEEE 9th International Conference on Dependable, Autonomic and Secure Computing.
[33]Daniel Berger, Fiodar Kazhamiaka, Esha Choukse, Inigo Goiri, Celine Irvene, Pulkit A. Misra, Alok Kumbhare, Rodrigo Fonseca, and Ricardo Bianchini. 2023. Research avenues towards net-zero cloud platforms. In 1st Workshop on NetZero Carbon Computing (NetZero’23).
[34]Chaojie Zhang, Alok Kumbhare, Ioannis Manousakis, Deli Zhang, Pulkit Misra, Rod Assis, Kyle Woolcock, Nithish Mahalingam, Brijesh Warrier, David Gauthier, Lalu Kunnath, Steve Solomon, Osvaldo Morales, Marcus Fontoura, and Ricardo Bianchini. 2021. Flex: High-availability datacenters with zero reserved power. In ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA’21). IEEE.
[35]Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. 2017. Amazon aurora: Design considerations for high throughput cloud-native relational databases. In ACM SIGMOD Conference. 1041–1052.
[36]Mohammad Alizadeh, Albert Greenberg, David A. Maltz, Jitendra Padhye, Parveen Patel, Balaji Prabhakar, Sudipta Sengupta, and Murari Sridharan. 2010. Data center TCP (DCTCP). In ACM SIGCOMM Conference. 63–74.
[37]Albert Greenberg, James R. Hamilton, Navendu Jain, Srikanth Kandula, Changhoon Kim, Parantap Lahiri, David A. Maltz, Parveen Patel, and Sudipta Sengupta. 2009. VL2: A scalable and flexible data center network. In ACM SIGCOMM Conference on Data Communication. 51–62.
[38]Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The demikernel datapath os architecture for microsecond-scale datacenter systems. In ACM SIGOPS 28th Symposium on Operating Systems Principles. 195–211.
[39]Andrew Putnam, Adrian M. Caulfield, Eric S. Chung, Derek Chiou, Kypros Constantinides, John Demme, Hadi Esmaeilzadeh, Jeremy Fowers, Gopi Prashanth Gopal, Jan Gray, Michael Haselman, Scott Hauck, Stephen Heil, Amir Hormati, Joo-Young Kim, Sitaram Lanka, James Larus, Eric Peterson, Simon Pope, Aaron Smith, Jason Thong, Phillip Yi Xiao, and Doug Burger. 2014. A reconfigurable fabric for accelerating large-scale datacenter services. ACM SIGARCH Comput. Archit. News 42, 3 (2014), 13–24.
[40]Daniel Firestone, Andrew Putnam, Sambhrama Mundkur, Derek Chiou, Alireza Dabagh, Mike Andrewartha, Hari Angepat, Vivek Bhanu, Adrian Caulfield, Eric Chung, Harish Kumar Chandrappa, Somesh Chaturmohta, Matt Humphrey, Jack Lavier, Norman Lam, Fengfen Liu, Kalin Ovtcharov, Jitu Padhye, Gautham Popuri, Shachar Raindel, Tejas Sapre, Mark Shaw, Gabriel Silva, Madhan Sivakumar, Nisheeth Srivastava, Anshuman Verma, Qasim Zuhair, Deepak Bansal, Doug Burger, Kushagra Vaid, David A. Maltz, and Albert Greenberg. 2018. Azure accelerated networking: SmartNICs in the public cloud. In USENIX Symposium on Networked Systems Design and Implementation (NSDI’18), 51–66.
[41]Tal Ben-Nun and Torsten Hoefler. 2019. Demystifying parallel and distributed deep learning: An in-depth concurrency analysis. ACM Comput. Surv. 52, 4 (2019), 1–43.
[42]Marcos K. Aguilera, Naama Ben-David, Rachid Guerraoui, Antoine Murat, Athanasios Xygkis, and Igor Zablotchi. 2023. uBFT: Microsecond-scale BFT using disaggregated memory. In ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS’23). 862–877.
[43]James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, J. J. Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Yasushi Saito, Michal Szymaniak, Christopher Taylor, Ruth Wang, and Dale Woodford. 2013. Spanner: Google's globally distributed database. ACM Trans. Comput. Syst. 31, 3 (2013), 1–22.
[44]Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernandez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chaitanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, and Vikram Wakade. 2019. Socrates: The new SQL server in the cloud. In ACM SIGMOD Conference. 1743–1756.
[45]Mahesh Natu and Thanu Rangarajan. 2020. Compute Express Link (CXL) Update. In UEFI 2020 Virtual Plugfest.
[46]UEFI. 2020. Coherent Device Attribute Table (CDAT) specification. Retrieved from uefi.org.
[47]M. S. Papamarcos and J. H. Patel. 1984. A low-overhead coherence solution for multiprocessors with private cache memories. In 11th Annual International Symposium on Computer Architecture (ISCA’84).
[48]Yan Sun, Yifan Yuan, Zeduo Yu, Reese Kuper, Chihun Song, Jinghan Huang, Houxiang Ji, Siddharth Agarwal, Jiaqi Lou, Ipoom Jeong, Ren Wang, Jung Ho Ahn, Tianyin Xu, and Nam Sung Kim. 2023. Demystifying CXL memory with genuine CXL-ready systems and devices. arXiv preprint arXiv:2303.15375 (2023).
[49]D. Gouk, M. Kwon, H. Bae, S. Lee, and M. Jung. 2023. Memory pooling with CXL. IEEE Micro 43, 2 (2023).
[50]J. Dastidar, D. Riddoch, J. Moore, S. Pope, and J. Wesselkamper. 2023. AMD 400G adaptive SmartNIC SoC–Technology preview. IEEE Micro 43, 3 (2023).
[51]D. Boles, D. Waddington, and D. A. Roberts. 2023. CXL-enabled enhanced memory functions. IEEE Micro 43, 2 (2023).
[52]Kyungsan Kim, Hyunseok Kim, Jinin So, Wonjae Lee, Junhyuk Im, Sungjoo Park, Jeonghyeon Cho, and Hoyoung Song. 2023. SMT: Software-Defined memory tiering for heterogeneous computing systems with CXL memory expander. IEEE Micro 43, 2 (2023), 20–29.
[53]Montage Technology. 2023. CXL Memory Expander Controller (MXC). Retrieved from https://www.montage-tech.com/MXC
[54]SK Hynix Inc. 2022. SK Hynix introduces industry's first CXL-based Computational Memory Solution (CMS) at the OCP Global Summit. Retrieved from https://news.skhynix.com/sk-hynix-introduces-industrysfirst-cxl-based-cms-at-the-ocp-global-summit/
[55]Parag Beeraka. 2023. Enabling CXL within the data center with arm solutions. In OpenCompute Summit. https://memverge.com/wp-content/uploads/2022/10/CXL-Forum-Wall-Street_arm.pdf
[56]Daniel S. Berger, Daniel Ernst, Huaicheng Li, Pantea Zardoshti, Monish Shah, Samir Rajadnya, Scott Lee, Lisa Hsu, Ishwar Agarwal, Mark D. Hill, and Ricardo Bianchini. 2023. Design tradeoffs in CXL-based memory pools for public cloud platforms. IEEE Micro 43, 2 (2023), 30–38.
[57]Nirav Atre, Justine Sherry, Weina Wang, and Daniel S. Berger. 2020. Caching with delayed hits. In Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication. 495–513.
[58]Davy Genbrugge and Lieven Eeckhout. 2007. Memory data flow modeling in statistical simulation for the efficient exploration of microprocessor design spaces. IEEE Trans. Comput. 57, 1 (2007), 41–54.
[59]Onur Mutlu and Lavanya Subramanian. 2014. Research problems and opportunities in memory systems. Supercomput. Front. Innov. 1, 3 (2014), 19–55.
[60]Kevin Kai-Wei Chang, Donghyuk Lee, Zeshan Chishti, Alaa R. Alameldeen, Chris Wilkerson, Yoongu Kim, and Onur Mutlu. 2014. Improving DRAM performance by parallelizing refreshes with accesses. In International Symposium on High-Performance Computer Architecture (HPCA’14).
[61]Jamie Liu, Ben Jaiyen, Richard Veras, and Onur Mutlu. 2012. RAIDR: Retention-aware intelligent DRAM refresh. In International Symposium on Computer Architecture (ISCA’12).
[62]Prashant J. Nair, Dae-Hyun Kim, and Moinuddin K. Qureshi. 2013. ArchShield: Architectural framework for assisting DRAM scaling by tolerating high error rates. In International Symposium on Computer Architecture (ISCA’13).
[63]Gennady Pekhimenko, Todd C. Mowry, and Onur Mutlu. 2013. Linearly compressed pages: A main memory compression framework with low complexity and low latency. In Annual IEEE/ACM International Symposium on Microarchitecture (MICRO’13).
[64]Esha Choukse, Mattan Erez, and Alaa R. Alameldeen. 2018. Compresso: Pragmatic main memory compression. In 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO’18). IEEE.
Go to Citation
[65]O. Mutlu, S. Ghose, J. Gómez-Luna, and R. Ausavarungnirun. 2022. A modern primer on processing in memory. In Emerging Computing: From Devices to Systems: Looking Beyond Moore and Von Neumann. Springer Nature Singapore, 171–243.
[66]Gagandeep Singh, Lorenzo Chelini, Stefano Corda, Ahsan Javed Awan, Sander Stuijk, Roel Jordans, Henk Corporaal, and Albert-Jan Boonstra. 2019. Near-memory computing: Past, present, and future. Microprocess. Microsyst. 71 (2019), 102868.
[67]H. Hassan, G. Pekhimenko, N. Vijaykumar, V. Seshadri, D. Lee, O. Ergin, and O. Mutlu. 2016. ChargeCache: Reducing DRAM latency by exploiting row access locality. In IEEE International Symposium on High Performance Computer Architecture (HPCA’16). 581–593.
[68]D. Lee, Y. Kim, G. Pekhimenko, S. Khan, V. Seshadri, K. Chang, and O. Mutlu. 2015. Adaptive-latency DRAM: Optimizing DRAM timing for the common-case. In IEEE 21st International Symposium on High Performance Computer Architecture (HPCA’15). 489–501.
[69]S. Lee, B. Jeon, K. Kang, D. Ka, N. Kim, Y. Kim, and J. Oh. 2019. 23.4 a 512GB 1.1 V managed DRAM solution with 16GB ODP and media controller. In IEEE International Solid-State Circuits Conference (ISSCC’19). 384–386.
[70]Y. Chen. 2020. ReRAM: History, status, and future. IEEE Trans. Electron Devices 67, 4 (2020), 1420–1433.
[71]F. T. Hady, A. Foong, B. Veal, and D. Williams. 2017. Platform storage performance with 3D XPoint technology. Proc. IEEE 105, 9 (2017), 1822–1833.
[72]D. Das Sharma. 2022. Universal Chiplet Interconnect express (UCIe)®: Building an open chiplet ecosystem. White paper. In UCIe Consortium.
[73]Debendra Das Sharma, Gerald Pasdast, Zhiguo Qian, and Kemal Aygun. 2022. Universal Chiplet Interconnect express (UCIe)®: An open industry standard for innovations with chiplets at package level. IEEE Trans. Compon., Packag., Manuf. Technol. (2022 Oct.).
[74]D. Das Sharma. 2023. Universal Chiplet Interconnect express (UCIe)®: An open industry standard for innovations with chiplets at package level. IEEE Micro Special Issue Mar.–Apr. Mar.–Apr. (2023.
[75]Micron. 2023. Micron launches memory expansion module portfolio to accelerate CXL 2.0 adoption. Retrieved from https://investors.micron.com/news-releases/news-release-details/micron-launches-memory-expansion-module-portfolio-accelerate-cxl
[76]Astera Labs. 2023. Leo CXL smart memory controllers. Retrieved from https://www.asteralabs.com/wp-content/uploads/2024/05/231220_Product_Brief_Leo_CXL_Smart_Memory_Controllers.pdf
[77]Microchip. 2023. SMC 2000 Smart Memory Controllers. Retrieved from https://ww1.microchip.com/downloads/aemDocuments/documents/DCS/ProductDocuments/Brochures/SMC-2000-Smart-Memory-Controllers-00004551.pdf
[78]Nam Sung Kim. 2018. Practical challenges in supporting function in memory. In IEEE Asian Solid-State Circuits Conference (A-SSCC’18). IEEE.
[79]Hao Wang, Chang-Jae Park, Gyungsu Byun, Jung Ho Ahn, and Nam Sung Kim. 2015. Alloy: Parallel-serial memory channel architecture for single-chip heterogeneous processor systems. In International Symposium on High-Performance Computer Architecture (HPCA’15).
[80]Y. Zhong, D. S. Berger, C. Waldspurger, I. Agarwal, R. Agarwal, F. Hady, K. Kumar, M. D. Hill, M. Chowdhury, and A. Cidon. 2024. Managing memory tiers with CXL in virtualized environments. In Symposium on Operating Systems Design and Implementation.
[81]Jaylen Wang, Daniel S. Berger, Fiodar Kazhamiaka, Celine Irvene, Chaojie Zhang, Esha Choukse, Kali Frost, Rodrigo Fonseca, Brijesh Warrier, Chetan Bansal, Jonathan Stern, Ricardo Bianchini, and Akshitha Sriraman. 2024. Designing cloud servers for lower carbon. In 51st Annual International Symposium on Computer Architecture.
[82]W. S. Cleveland配资知识开户, E. Grosse and W. M. Shyu. 1992. Local regression models. In Statistical Models in S, J. M. Chambers and T. J. Hastie (Eds.). Wadsworth & Brooks/Cole.